こんにちは、エンジニアの渡辺(@mochi_neko_7)です。
今回は Unity でランタイム(アプリケーション実行中)に読み込んだ Humanoid モデルに、同じくランタイムに読み込んだモーションを適用できるようにするまでの流れを解説します。
ユースケースが多くないのか世の中にあまり情報が多くない印象だったので、同様のことをされる方に参考になれば幸いです。
想定しているユースケースの一例としてはモーションビューワーで、ランタイムで外部からモーションデータを読み込んで、適当な Humanoid モデルにモーションを適用するものです。
少し前の記事 でチラッと紹介したようにモーション生成 AI も出始めているので、それを見越したものにもなります。
特別記事の内容に影響はありませんが、検証に使用している Unity のバージョンは下記です。
- Unity 2022.3.0f1
- ワークフローの確認
- Humanoid モデルの読み込み
- Generic アニメーションの使用
- BVH のモーションの読み込み
- FBX のモーションの読み込み
- Generic アニメーションのための Path の変換
- T-Pose の異なるアバター間のモーション変換
- Playable API によるモーション適用
- 結果の例
- 要点
- おわりに
ワークフローの確認
全体の見通しが良くなるようワークフローを先にまとめます。
- Humanoid モデルの読み込み
- モーションデータの読み込み
- Generic アニメーションの Path の変換
- T-Pose の異なるアバター間のモーション変換
- Playable API によるモーション適用
これらを Unity Editor 上の開発時ではなく、ランタイム(アプリケーション実行中)に行っていきます。
あくまで一例に過ぎませんが、実現するまでに以外と多くのステップを挟む必要があります。
一つずつ順番に見ていきましょう。
Humanoid モデルの読み込み
Humanoid モデルの読み込みに関しては過去に記事を書いていますので、こちらを参照してください。
今回はシンプルに UniVRM を用いて VRM アバターをロードして使用します。
読み込んだ Humanoid モデル用にセットアップされている isHuman = true な Avatar があることを確認してください。
Generic アニメーションの使用
Unity におけるモーションデータの表現として一般的なものは AnimationClip になります。
AnimationClip にはいくつか属性がありますが、特に下記の2点に注意が必要です。
- legacy
- humanMotion
- Humanoid アニメーションの場合は
true、Generic アニメーションの場合はfalseが返ってきます。
- Humanoid アニメーションの場合は
Humanoid モデルのアニメーションは Avatar を Animator にセットして Humanoid アニメーションを使用するのが基本だと思います。
ただ動的に生成した AnimationClip の humanMotion を true にする方法(条件)が分からないため、本記事では仕方なく Generic アニメーションを使用することを前提にして話を進めます。
※ もしランタイムで生成した AnimationClip を humanMotion = true にできる方法をご存知の方がいましたら教えていただきたいです。*1
Generic アニメーションでは各ボーンの Transform 上の名前でアニメーションを組みますが、モーションデータをロードした際にはそのモーションに入っているモデルのボーン名を用いた Path でロードされることが多いです。
しかし今回のようにアニメーションデータ内のモデルとは別のモデルにアニメーションを適用したい場合には、アニメーションを適用したい先のモデルのボーン名を用いた Path で AnimationClip を作成する必要があります。
そのため、Generic アニメーションの AnimationClip 生成の際の Path の指定の仕方に配慮する必要があります。
BVH のモーションの読み込み
BVH(.bvh)はテキストベースのモーションファイルフォーマットの一つで、Biovision 社という現存しない会社が提唱したものですが、モーション関連では現在でも一般的に使われている印象です。
BVH のランタイム読み込むはもちろん Unity は標準対応していないため*2外部ライブラリが必要ですが、実は UniVRM の中の UniGLTF、の中の UniHumanoid に BVH Importer が実装されています。
基本的にはこちらを使用すればよいですが、後述するようにボーン名の変換や T-Pose の差分の考慮が必要になるため、実際には BVH の Parse されたモーションデータ(UniHumanoid.Bvh)だけ拝借して AnimationClip 生成部分は自分で書き直すことになります。
FBX のモーションの読み込み
汎用 3D モデルフォーマットの FBX(.fbx)もモーションデータを持つことができるため、モーション関連で使用されることが多いかと思います。
UnityEditor では FBX のインポートに標準対応していますが、ランタイムでのインポートには対応していません。
FBX 用のランタイムライブラリとして自分がよく使用するのは、TriLib という有料アセットです。 assetstore.unity.com
各種フォーマット、各種プラットフォームにも対応していて使い勝手が良いです。
TriLib には AssetLoaderOptions というロード設定があり、「Animations」設定もありますが、「Rig」の設定で Humanoid に設定しても生成される AnimationClip は Generic アニメーションになります。

この時生成される AnimationClip は当然 FBX ファイル内のモデルに対する Generic アニメーションですので、BVH 同様ロードされたモーションのデータのみ使用し、AnimationClip は Path の変換や T-Pose の補正をかけて自分で再生成することになります。
ロードされたモーションの元データは AssetLoaderContext.RootModel.AllAnimations の中に入っていて、AnimationClip の生成に必要な情報は揃っています。
ちなみに今回は触れませんが glTF も FBX 同様モーションデータを持つことができますが、TriLib は glTF にも対応しているためほぼ同様の手順で glTF のアニメーションデータも読み込むことができます。
Generic アニメーションのための Path の変換
Generic アニメーションの使用 で説明したように、とあるモデルに合わせて作成されている Generic アニメーションのデータはそのモデル固有のボーン名の Path で構成されており、異なるモデルにそのまま適用しても Path が異なる場合にはアニメーションさせることはできません。
ですが Humanoid 想定のモデルであれば Avatar が生成でき、Unity の HumanBodyBones でキーポイントとなるボーンが規格化されています。
ということは下記のようなステップで一方のモデルの Path から相互の Avatar を通してもう一方の Path に変換することは難しくありません。
- とあるボーンの Path の末尾のボーン名を取得する
- そのモデルの
Avatar.humanDescription.humanからボーン名で検索をし、HumanBone.humanNameを特定する - 同じ humanName をもつ HumanBone を適用先の Avatar から検索をし、ボーン名を特定する
- 適用先の Transform から特定したボーン名の Transform の子供を探し、親に辿って Path を構成する
注意点としては当然 Humanoid のボーンの仕様外のアニメーションは変換できませんが、それは Humanoid アニメーションも同じ仕様なので大きな問題にはならないかと思います。
T-Pose の異なるアバター間のモーション変換
3D モデルの作り方には標準規格がなく、Humanoid モデルといっても作り手によって様々な仕様で作られるモデルが存在します。
使用する 3D CG ソフトの違いによる右手系 / 左手系や y-up / z-up の座標系の違いも有名ですが、Humanoid のボーンの向きの付け方にも様々あります。
例えば VRM モデルは T-Pose で全てのボーンがほぼ無回転、つまり 右側が x 方向、上側が y 方向、前側が z 方向を向きますが、とある FBX モデルではパーツの末端方法に y 軸が向く、いわゆる y-forward なものも存在します。*3
後者では T-Pose 時に y-forward 分の回転が入るため、同じ T-Pose でも VRM と FBX では姿勢が異なる、という場面が起こります。
- VRM の Left Upper Leg:
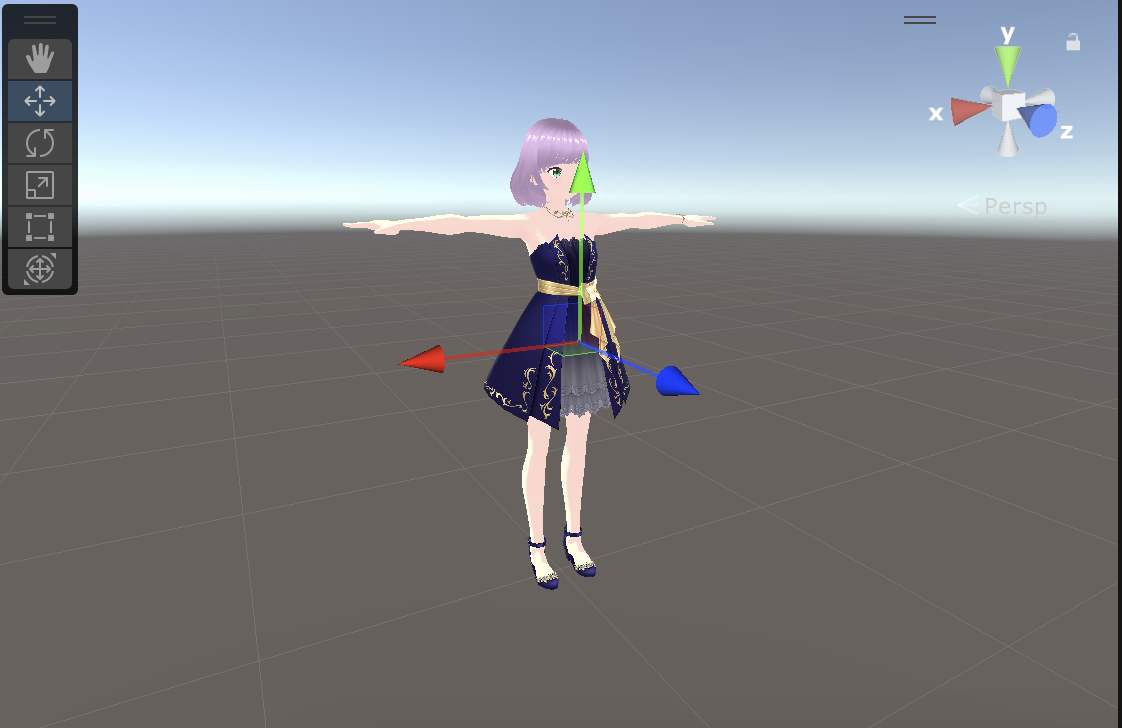
- とある FBX の Left Upper Leg
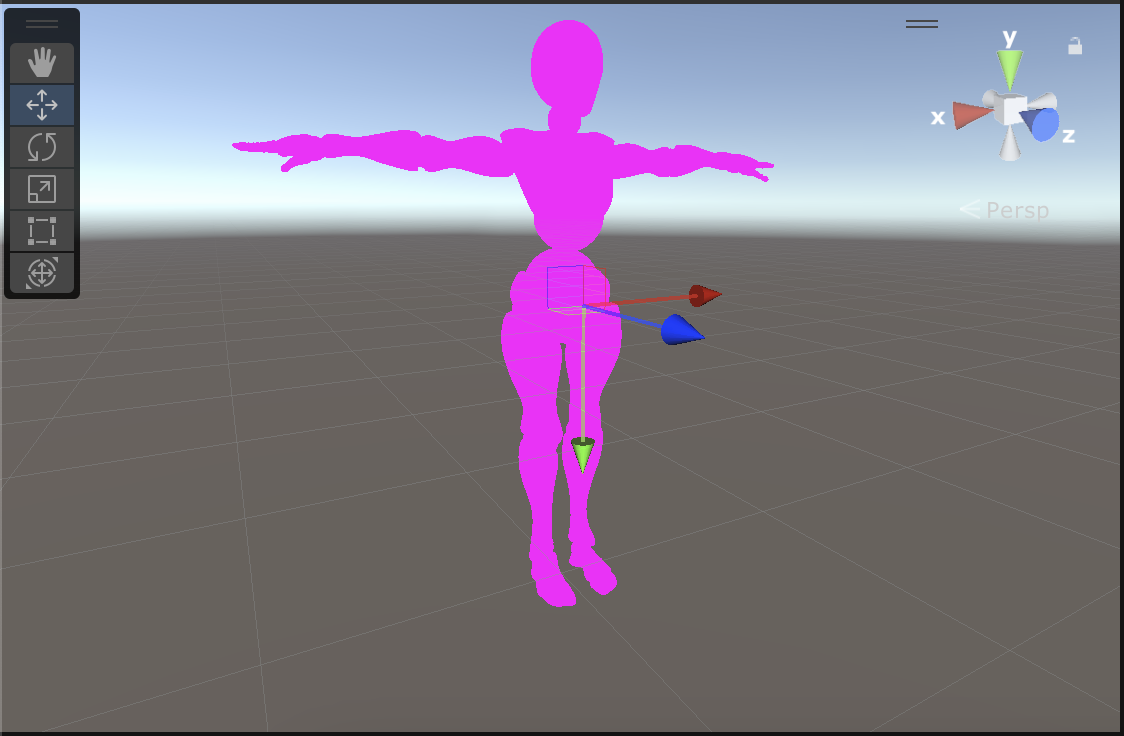
このような T-Pose の姿勢の違うモデル間でアニメーションをそのまま適用しても、結果が同じ姿勢にはなりません。
(結果の例 をご覧ください)
VRM モデルの T-Pose が無回転に近いので、簡単のために適用先のモデルを VRM として適用先の回転を無視する場合を考えてみましょう。
この VRM モデルに対して、y-forward な FBX モデルのアニメーションを適用するための変換式は、FBX モデルの T-Pose 時のとあるボーンの Local Rotation を 、Transform の親の World Rotation を
、元の FBX モデルの該当ボーンのアニメーションのとあるフレームの Local Rotation を
とすると、VRM モデルに適用するために変換されたアニメーションの Local Rotation
は
と表現できます。
これらの量は全て Quaternion なので積が非可換であること、右肩の -1 は Unity での Quaternion.Inverse(...) に相当することに注意します。
の部分は FBX の T-Pose の Local Rotation
を差し引いているものです。
のように親の World Rotation で挟んでいるのは、Transform の回転は親の影響を受けるために親の回転を引いた姿勢で Local Rotation を再計算するためです。
Transform 親から順番に回転を適用していくので、例えば 1 -> 2 -> 3 の順で親から子に辿った時の子の World の回転は のように右から Quaternion をかけていきます。
この親の回転を一度打ち消すために右から をかけ、更に親の回転自体は Local Rotation 自体の計算には不要であくまで軸が回転していることだけを取り入れたいため、もう一度
をかけて Local の回転に戻してあげます。(親の回転分だけ座標系が回転しているので、座標系間の変換をしているイメージです)
簡単のために VRM の回転を無視していますが、実際には VRM モデルの Local Rotation、親の World Rotation も追加で考慮する必要があります。
VRM は上記だけでもそれなりに綺麗に変換できるためあまり検証できていませんが、おそらく同様に VRM の Local Rotation を加え、VRM の親の World Rotation で両側から挟むような形になることと、変換の対称性*4を考えると下記のような形になるかと思います。
同様の説明が VRM Animation の「ポーズデータの互換性について」 にも記載があります。
式の見かけは一見違いますが、 で書き直すと一致することが確認できます。
Playable API によるモーション適用
通常 UnityEditor 上で FBX などの 3D モデルデータをインポートして AnimationClip を作成し、AnimatorController や Timeline に載せてモーションを適用することが多いかと思います。
しかし今回のアプローチでは適用先のモデルも適応したいモーションもランタイムで読み込んで使用することを想定しています。
(Runtime) AnimatorController の API をよく眺めてみると、AnimationClip を追加・編集するような API は見当らず、あくまで Readonly で参照できるだけのようです。
代替手段としては少し古い API の Animation *5、もしくは Timeline のベースにもなっている Playable API を使用することができます。
今回はより新しいアプローチの Playable API を使用します。
Playable API による AnimationClip の再生に関しては下記記事などを参照してください。
一つの 3D モデルに複数のモーションデータが入っている場合もあるため、AnimationMixerPlayer を使うのがベターかと思います。
結果の例
Mixamo の Hip Hop Dancing(FBX)を実際に適用した例です。

ちなみに閲覧注意ですが上記を T-Pose の補正をせずにモーションを適用したのが下記です。

別サービスのモーションの例として、Vmotionize の Text to Motion で生成された泳ぎモーション(FBX)を使用したのが下記です。

VRM モデルは VRoid 製の自作のものを使用しています。
要点
処理をややこしくしているのは主に下記の点になります。
- 外部ファイルのランタイムでの読み込みに外部のライブラリを使用する必要がある
- 動的に読み込んだ AnimationClip を Humanoid にする設定方法が分からず、Humanoid アニメーションが使用できないこと
- Generic アニメーションにおける適切な Path 設定が必要なこと
- T-Pose の異なるモデル間のモーションの変換が必要なこと
結果的に前述のアプローチでうまくアニメーションを適用することには成功しましたが、Humanoid アニメーションとしてロードする方法が分かればもう少し楽できるはずです。
おわりに
Unity のアニメーションの仕組みに関してはそこまで理解していなかったですが、UnityEngine.Avatar や Quaternion の知識はあったおかげで最終的には見られる状態まで持っていくことができました。
本来はいつものようにライブラリを公開したいところですが、外部のライブラリに依存している部分が大きいこと、様々なパターンのモデルを網羅的にデバッグするとこまでは検証ができていないことから、本記事では考え方の解説に留めます。
Generic アニメーションで遠回りな実装ではありますが、改めて普段何気なく利用していた Humanoid アニメーションのありがたみを感じます。
あとはモーションデータのフォーマットとしても BVH は仕様が少し曖昧かつテキストベースでデータの無駄が多いこと、FBX や glTF は汎用フォーマットで情報量が多いことなど気になる点が多いですし、もう少しシンプルで扱いやすいフォーマットがあってもいいのではと思いました。( VRM Animation のモチベーションのそれかもしれませんが、まだ使える場面が限定的です。)
単位や座標系の違いをフォーマットの仕様で制限して、ライブラリ側で各 3D エンジン向けの変換をする方が賢い気がします。
将来的にはポーズデータを生成系 AI でリアルタイムに生成してアニメーションさせる、なんて時代が来た場合には外部から取り込んだモーションデータの適用が重要になるかもしれません。
以上、Unity におけるランタイムでのアニメーションの読み込みと適用に関して参考になれば幸いです。