 こんにちは。Activ8の岡村です。
こんにちは。Activ8の岡村です。
最近Activ8社内で生成AIハッカソンが行われたため、それに向けて作った簡単なUnityアプリをせっかくなので紹介します。*1
アプリの内容は、カメラで撮影した画像をAIに見せてプロンプトを生成し、生成したプロンプトで画像生成する、といったものです。
デモ
汚くて申し訳ないですが、自分の机の写真を用意しました。
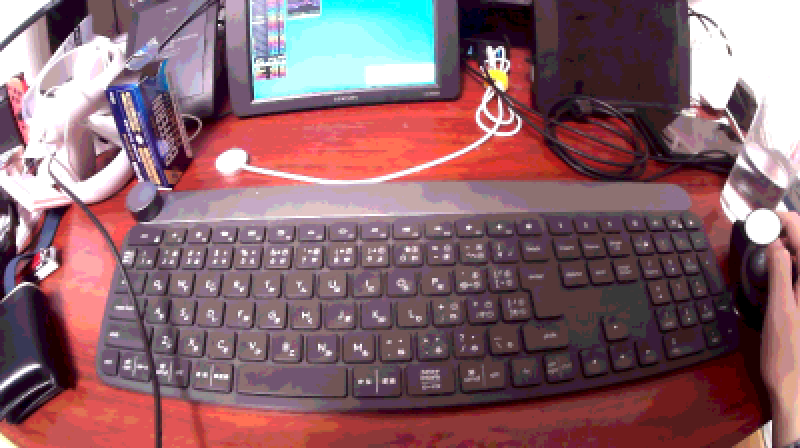 ↓
↓
The photo appears to depict a cluttered workstation from a first-person perspective. At the forefront, there is a black, full-sized keyboard with Japanese characters on the keys alongside the standard English letters and numbers, suggesting a bilingual user interface. To the right of the keyboard is a person’s right hand controlling a vertical ergonomic mouse, and further right is a clear glass of water positioned close to the edge of the desk. Just beyond the keyboard, across the bottom edge of the photo, a white earbud with a long cable trails across the work surface, and next to it, a black wristwatch is placed face-down. To the left, there’s a large gaming headset resting on top of a closed laptop, its size dominating a significant part of the desk’s left side. Next to the headset is a small stack of personal items including what seems to be a card pack for a collectible card game. In the background, there are two monitors; the left one has a colorful display that could be a puzzle or strategy game, and the right one is turned off, reflecting the surrounding room. There are various cables and other objects, including a Nintendo Switch, revealing a certain unorganized, lived-in quality to the space. The entire scene is indicative of a tech-savvy individual with various interests in gaming, technology, and possibly language studies or translation work. The image captures a candid, everyday moment of someone's personal workspace.
↓

すごく似ている、というわけでもないのですが、画像に映っているところどころのオブジェクトは再現されており、不思議な近親感を持つ画像に仕上がっています。
前提
- 2023年12月9日時点の情報
- OpenAI API
- Unity 2022.3.11f1
- Windows 10
Unityを使っているのは単純に私自身がUnityに慣れているからです。あと、時間があればUIを作りこんだりスマホ対応したかったな……というのもあります。
構想
発想当時はChatGPTが画像認識、画像生成に対応したタイミングであったため、このマルチモーダル機能を活かしたものを作りたいと考えていました。特に画像認識能力は既にOpenAI APIにも搭載されており、gpt-4-vision-previewモデルとして利用可能になっています。なので、画像を認識して説明し、それを基に加工された画像を用意する、といった仕組みの作成に挑戦してみました。
ちなみに、似た画像を生成するだけならDALL-EにCreate image variation機能があるのですが、こちらはプロンプトの指定ができません。プロンプトの指定ができると、画像の加工時に情報の追加や削除が柔軟にできて可能性が広がるのではと考え、一度プロンプトに変換する方法を試してみました。
実装
突貫で作ったのもありあんまり見せられたコードではないのですが、かいつまんで紹介していきます。
アプリ自体のつくりはシンプルで、撮影し、加工して、結果を見るという3ステートで構成されており、ステートの管理はImtStateMachineを使用しました。
撮影ステートでは、カメラの映像をWebCamTextureで取得し、撮影ボタンを押したら新しいテクスチャを作成してデータをコピーします。
public Texture TakeSnapShot()
{
var destTexture = new Texture2D(texture.width, texture.height, DefaultFormat.Video, TextureCreationFlags.None);
destTexture.SetPixels32(texture.GetPixels32());
destTexture.Apply();
return destTexture;
}
加工ステートではテクスチャをjpegに変換し、OpenAIにアップロードしています。
var gpuRequest = await AsyncGPUReadback.Request(texture, 0, TextureFormat.RGBA32);
if (gpuRequest.hasError)
{
throw new Exception("Failed to readback texture.");
}
var data = gpuRequest.GetData<Color32>();
var jpg = ImageConversion.EncodeNativeArrayToJPG(data, texture.graphicsFormat, (uint)texture.width,
(uint)texture.height, 0);
return Convert.ToBase64String(jpg);
base64エンコードしたjpeg画像を、「この画像を画像生成のプロンプトに使えるくらい詳細に説明してください」といった感じのプロンプトとともにHttpRequestで投げています。
var request = new HttpRequestMessage(HttpMethod.Post, "https://api.openai.com/v1/chat/completions");
request.Headers.Add("Authorization", $"Bearer {apiKey}");
request.Content = new StringContent(
@$"{{
""model"": ""gpt-4-vision-preview"",
""messages"": [
{{
""role"": ""user"",
""content"": [
{{
""type"": ""text"",
""text"": ""Please describe the photo in enough detail to use it as a prompt for model generation.""
}},
{{
""type"": ""image_url"",
""image_url"": {{
""url"": ""data:image/jpg;base64,{await GetBase64EncodedJpegTexture(image.Texture)}""
}}
}}
]
}}
],
""max_tokens"": 300
}}", Encoding.UTF8, "application/json");
var responseMessage = await httpClient.SendAsync(request, token);
こうして受け取ったプロンプトを基に、DALL-E3で画像生成を行います。
var request = new HttpRequestMessage(HttpMethod.Post, "https://api.openai.com/v1/images/generations");
request.Headers.Add("Authorization", $"Bearer {apiKey}");
var content = new ByteArrayContent(Encoding.UTF8.GetBytes(
@$"{{
""model"": ""dall-e-3"",
""prompt"": ""{HttpUtility.JavaScriptStringEncode(prompt)}"",
""n"": 1,
""size"": ""1792x1024""
}}"));
content.Headers.ContentType = new System.Net.Http.Headers.MediaTypeHeaderValue("application/json");
request.Content = content;
var responseMessage = await httpClient.SendAsync(request, token);
最後に画像生成した結果をダウンロードし、テクスチャとして使えるようにしておしまいです。
var request = new HttpRequestMessage(HttpMethod.Get, url); var responseMessage = await httpClient.SendAsync(request, token); var response = await responseMessage.Content.ReadAsByteArrayAsync(); var texture = new Texture2D(1, 1); texture.LoadImage(response);
振り返り
Unityでの画像の扱いは以前からGPU周りの事情などが絡んでいて負荷を避けるのが難しいのですが、最近はAsyncGPUReadbackやImageConversionなどのAPIが生えていて、だいぶ楽になっているように感じました。上記コードではまだ妥協して古いAPIを使ってしまっているところが多いので、後でよりフレームレートに優しいコードに変えておきます。
OpenAI APIをC#から直接叩く際、Jsonペイロードの用意が中々面倒でした。元々C#とJsonの相性がいまいちなのもありますが、特に理不尽なところとして、chat/completionsではContent-TypeヘッダがStringContentクラスが生成するapplication/json; charset=utf-8のままでも問題なく使えたのですが、images/generationsではapplication/jsonでないとエラーが出てしまい、回避のためにByteArrayContentクラスを使わなければなりませんでした。
APIKeyの流出問題もあるので、公開するアプリではきちんと間にサーバーを挟んであげることをおすすめします。
また、生成の結果によってはコンテンツポリシーに違反しているというエラーが発生することもあり、日常の画像を使う際にはこういったエラーのハンドリングにも気を付ける必要がありそうです。
400 - BadRequest
{
"error": {
"code": "content_policy_violation",
"message": "Your request was rejected as a result of our safety system. Your prompt may contain text that is not allowed by our safety system.",
"param": null,
"type": "invalid_request_error"
}
}
画像を取り扱うAPIはコストも高く、2023年12月9日現在、プロンプト生成→画像生成の一連の流れで0.1ドル程度かかってしまっていたので、試す場合はコストにもご注意ください。画像認識のdetailを下げることで多少は回避できますが、クオリティとのトレードオフになります。
*1:体調不良で結局間に合いませんでした……