
こんにちは、エンジニアの渡辺(@mochi_neko_7)です。
今回は Rust の candle という ML(Machine Learning) フレームワークを使用して、BlazeFace というモデルを用いた顔検出(Face Detection)を趣味開発で実装した話を紹介します。
Rust で ML をやること自体まだ珍しいかと思いますし、Rust で実装されている candle は開発中というのもあり情報が少ないので使用例の一つとして参考になればと思います。
BlazeFace を選んだ理由は、私自身 ML は初心者のため実装が比較的シンプルなモデル*1を自分で実装してみたかったこと、VTuber 向けの Face Tracking システムがどのようにできているか興味を持った中で Face Detection がワークフローの最初のステップに実行される汎用的なもの*2であることで、実用性よりは個人的な勉強の色が強いです。
ですが candle は Pure Rust で実装されていてクロスプラットフォームの対応ができること、WebAssembly 対応がありブラウザでの利用も可能なこと、Rust の性能とメンテナンス性の高さ*3、Unity/C# への組み込みも現実的であること*4から、プロダクションにおける実用性もパフォーマンス次第ではあるかもしれません。
本記事では下記のような読者を想定しています。
- ML を触ったことがあり Rust / candle での実装に興味がある方
- PyTorch の実装との比較ができるかと思います
- ML 初心者で基礎理論は理解していて、具体的な実装例を見てみたい方
- 私自身がこの立場のため
- 個人的には Python より Rust の方が型が明示的で実装が読みやすいのではと思っています
ソースコードは下記の Repository で公開していますが、crate として公開する準備をまだ整えていないこと、クロスプラットフォームの動作検証ができていないことからすぐに製品利用することは難しいことにご注意ください。
使用している環境は下記になります。
- Windows 11
- NVIDIA GeForce RTX 4090
- CUDA 11.8 / cuDNN 8
- Rust v1.73.0
- candle v0.3.0 (#73d02f4f57c788c43f3e11991635bc15701c25c0)
candle とは
candle は HuggingFace が開発している Rust 製の ML フレームワークです。
API の比較表があるように PyTorch に近い API 構成をしていますので、PyTorch を触ったことのある方なら直感的に触れるかと思います。*5
既存の PyTorch や TensorFlow の ML フレームワーク は良くも悪くも成熟していて、Rust Bindings (例えば PyTorch に対する tch-rs) のバイナリサイズが大きくなってしまいます。
それに対して candle は Pure Rust で軽量な ML フレームワークを提供します。
そもそも Python は GIL などパフォーマンスに難があり、実戦でそのまま導入するには懸念が出るケースもあります。(実際に Mojo のような言語によるアプローチも開発されています。)
その点 Rust は実行速度が速かったり、WebAssembly にビルドしてブラウザで高速に動かすこともしやすいなどのメリットがあります。*6
反面、Rust での ML は環境が未成熟であったり、candle 自身もまだ開発中だったりする点に注意が必要です。
candle は examples で最新のモデルの実装例があり興味を持ったこと、API が PyTorch に近いので PyTorch の勉強にもなることから採用しました。
BlazeFace とは
今回実装する機械学習モデルは、BlazeFace という顔検出(Face Detection)のモデルです。
画像中の人間の顔を検出し、それぞれの顔の Bounding Box と6点のキーポイント(右目、左目、鼻、口、右耳、左耳)の位置、スコアを推定します。
Google が開発したモバイル端末の CPU でも動作することを目指したモデルで、MediaPipe の中に含まれている Face Detection でも使用されています。
BlazeFace のモデルのバックボーンとして、論文の Figure 1 に書かれているような BlazeBlock という二層の CNN をベースとした構造を利用します。
これは顔検出タスクでよく使用されている MobileNetV2 のパフォーマンスを改良したものになります。
顔検出タスクではニューラルネットワークを使用しない CV(Conputer Vision)の実装として例えば dlib の Face Detector などもよく使用されていますがロバストネスに課題があり、ニューラルネットワークを使用したモデルではこれを改善できるとのことです。*7
スマホのフロントカメラを想定した 128x128 の解像度の画像を入力とする Front モデル、バックカメラを想定した 256x256 の解像度の画像を入力とする Back モデルの二種類が実装されており、それぞれアーキテクチャもパラメータも異なります。
candle は PyTorch のパラメータファイル(.pth)も対応していますが挙動が不安定な部分*8もありますので、Safetensors(.safetensors)に変換して利用します。
BlazeFace の API は下記のような形です。
- 入力
- 128x128 もしくは 256x256 の画像(3チャネル)
- バッチ処理、つまり一度に複数の画像を入力することも可能
- 出力:
- 各画像で検出した人数分の17成分の1次元 Tensor のリスト
- 1 ~ 4:顔の Bounding Box の 左上(y min、x min)と右下(y max, x max)
- 5 ~ 16:顔の6点のキーポイント(右目、左目、鼻、口、右耳、左耳)の座標(y、x)
- 17: 信頼度スコア
candle を使った BlazeFace の再実装
BlazeFace 本家は TensorFlow で実装されていますが、candle により近い PyTorch 実装をされている Repository があったのでこちらを参考にさせてもらいました。
BlazeFace の実装はいくつかのステップを踏む必要があります。
- BlazeBlock の実装
- Front モデルと Back モデルの実装
- 推論結果の後処理の実装
- Non-maximum Supression の実装
- 最終的な BlazeFace の API の実装
- 画像の入出力処理の実装
1. BlazeBlock の実装
バックボーンとなる BlazeBlock および FinalBlazeBlock を PyTorch の実装を参考に candle で実装します。
face-tracking-rs/src/blaze_face/blaze_block.rs at main · mochi-neko/face-tracking-rs · GitHub
BlazeBlock は Stride が1と2の場合で処理に分岐があるため、上記ではそれぞれを明確に分けて実装しています。
また、Back モデルでは Stride は2でも Max Pooling と Channel Padding を適用しない FinalBlazeBlock も使用されるため、こちらも別で実装します。
face-tracking-rs/src/blaze_face/final_blaze_block.rs at main · mochi-neko/face-tracking-rs · GitHub
mod tests { ... } で Shape のチェックだけするテストコードも書いておきます。
2. Front モデルと Back モデルの実装
Conv2d レイヤーと BlazeBlock、FinalBlazeBlock を組み合わせた Front モデルと Back モデルをそれぞれ PyTorch 実装を参考にしながら実装します。
基本的には入り口の Conv2d → ReLU 活性化 → 複数の BlazeBlock → Classifier と Regression というフローの推論をします。
最後は Classifier にかけてスコアの推定を、Regression にかけて Bounding Box や Keypoint の位置の回帰推定をします。
ライブラリの Tensor という構造体は C# における Object 型のようなもので、実際の値に加えて Device(CPU or GPU)、DType(32bit float、16bit float などのパラメータの値型)、Shape(Tensor の形状、各成分の次元)があり、コンパイルは通っても実行時にそれらの不整合があるとエラーを出してしまいます。
特に Shape は不整合が起こりやすいため、それぞれ入力の Tensor の Shape が (batch_size, 3, 128, 128)、(batch_size, 3, 256, 256) であることを念頭に、計算過程の Tensor の Shape がどうなっているか確認しながら実装をし、丁寧にテストコードも書いておきます。
candle では .pth (PyTorch のパラメータファイル)、.safetensors (HuggingFace が定義しているパラメータファイル)などのパラメータファイルから candle_nn::VarBuilder を通して Weight や Bias などのパラメータをロードできますので、それに合わせたロード処理も実装しておきます。
3. 推論結果の後処理の実装
生の推論結果の Tensor はそのまま使用するのではなく、
- 回帰の結果を Anchor を使用して Pixel の座標系に変換(デコード)する
- Bounding Box は Center + Size → Min + Max に変換する
- スコアのフィルタリングをする
などをして扱いやすいよう加工しておきます。
4. Non-maximum Supression の実装
物体検出で一般的に使用される Non-maximum Supression を実装して、同じ人物の顔の検出結果をまとめます。
一定以上の重なりのある Box 同士を判定し、Score による重心の計算をして同じ顔の位置を補正し、Score は平均を取ります。
Non-maximum Supression の詳しい解説は下記を参照してください。
5. 最終的な BlazeFace の API の実装
2 ~ 4 をつなぎ合わせて、最終的な API を実装します。
- 入力
- 128x128 もしくは 256x256 の画像(3 Channels)
- バッチ処理、つまり一度に複数の画像を入力することも可能
- 出力:
- 各画像で検出した人数分の17成分の一次元 Tensor のリスト
- 1 ~ 4:顔の Bounding Box の 左上(y min、x min)と右下(y max, x max)
- 5 ~ 16:顔の6点のキーポイント(右目、左目、鼻、口、右耳、左耳)の座標(y、x)
- 17: 信頼度スコア
また、Rust 上で結果を扱う場合には Tensor ではなく明示的に構造体を用意した方が触りやすいため、Tensor → 構造体(FaceDetection)の変換処理もオプションで用意しておきます。
face-tracking-rs/src/blaze_face/face_detection.rs at main · mochi-neko/face-tracking-rs · GitHub
各モデルの forward 処理の終盤の permute、resize をよく追うと座標の順番が x、y ではなく y、x の順番になっている点に注意します。*9
PyTorch の実装ではなぜかこの順番が不自然だったので修正をして実装をしています。
6. 画像の入出力処理の実装
Rust 上での画像の入出力は image crate、加工処理は imageproc crate が利用できます。
Tensor の順番や解像度などに気を遣う必要があるので少し注意が必要ですが、これらの外部 crate に直接依存するのは避けたいため現在は examples 内に実装を用意しています。
もしかしたら後で本体側にも実装を用意するかもしれません。
実行例
photoAC からライセンスフリーの写真をお借りして BlazeFace を実行してみた例が下記です。
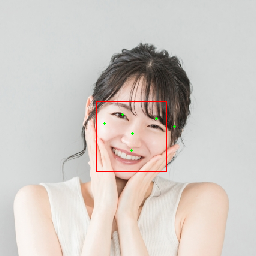
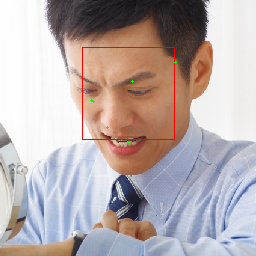




一人の場合は多少角度がついていても検出自体はできていることが分かります。
ただ Bounding Box のサイズや Keypoint の位置のずれが気になりますし、多人数の場合の結果が近い顔に密集していて不自然なので、Non-maximum Supression などの実装かパラメータ設定に不備があるかもしれません。
ベンチマーク
ベンチマークで実際の処理負荷の計測結果を公開したいところですが、普段開発に利用しているのが Docker (WSL2)環境であること、CUDA を使用すると実行時に謎のエラーが出たり、CPU では MKL のコンパイルが通らないことなどあり、まともな結果をまだお見せすることができません。
Windows ローカルで MKL なし、Front モデルが 21ms 前後と想定より遅すぎるので、最適化すべき実装が多分に残っていると思われます。
正しく計測できた際には Repository の README に記載する予定ですので、少しお待ちください。
活用例
BlazeFace の Face Detection は顔関係のタスク、例えば Face Landmark Detection(顔の特徴点検出)の前処理としても利用されます。
実例としては Media Pipe の Face Landmarker でも BlaceFace が使用されています。
Face landmark detection guide | MediaPipe | Google for Developers
そのため、Face Detection 単体ではなくより高度なタスクと組み合わせることでより BlazeFace の軽量さに価値が出るかと思います。
おわりに
実行例でお見せしたように、一応実際に candle / Rust を使った BlaceFace の Face Detection が実装できました。
とはいえ想定より少し精度が低い点、複数人の場合の処理が怪しい点、ベンチマークによる最適化対応ができていない点など課題も多く残っています。
これらの対応が落ち着いたら、次の目標の Face Landmark Detection に挑戦しようと思います。
candle / Rust で BlazeFace を実装してみた感想もいくつか述べておきます。
- Rust の型システムのおかげで途中処理が追いやすい
- Python だと Type Hints を使っている実装が少なくて理解に時間がかかる場合も多いですが、Rust だと明示的で理解しやすいと個人的に思います
- とはいえ Tensor は candle でも PyTorch 同様、実装ミスによる Shape や DType などの実行時エラーが起こりやすく、テストコードを書きながら実装しないとデバッグが大変になりそうです
- ML の基礎の再確認になった
- CNN の挙動やパラメータファイルの IO など、ML 初心者の自分には手を動かすことで勉強になりました
- PyTorch との差分は当然ある
- 特に Tensor の Setter がない点、Mask の実装に少し工夫が必要な点に注意が必要でした
- ただし candle のアップデートで変わる可能性もあります
- 再実装でもそれなりに時間はかかる
- 参考になる PyTorch 実装があっても、テストコードを書きながら実装してもやはりそれなりに時間がかかりました(慣れの問題もありますが)
- Rust の cargo(パッケージ管理)、rustfmt(フォーマッター)、criterion(ベンチマーク)などのエコシステムが優秀で開発が快適
なにより Rust で ML を書ける、学べるのは楽しいので、Rust が好きで ML に興味がある方は candle から入門してみるのもありかもしれません。
*1:BlazeFace は CNN ベースで特に難しい構造は登場しません
*2:例えば顔の形状を取る Face Landmark Detection でも始めに Face Detection をして人物の有無、顔の位置の特定をします
*3:Python と比較して
*4:csbindgen で Rust -> C# API の変換ができるため
*5:名前も Torch(松明)に対する蝋燭(Candle)というアナロジーでしょうね
*6:もちろん Python でも裏側の実装を C や C++ で書いて高速化するケースも多いですが、再実装の手間やメモリ安全性の問題などもあります。
*7:詳細:https://arxiv.org/pdf/2101.10808.pdf
*8:Linux では問題なかったですが、Windows だとロードエラーになりました。
*9:元が height, width の順番なので