LTレポ「SentenceBERTを使って「草」や動画チャットのコメントの特徴を追ってみた」
広報の熊谷(@spirea_xxx)です!
2023年5月をもってSynamonとActiv8は経営統合をしたのですが、統合後の社内イベント第一弾として5月2日に「生成系AI活用について」をテーマに社内ハッカソンを開催しました!
会場はSynamonオフィス、オンラインでも参加ができるように配信環境を整えての実施でした。
ハッカソンといっても今回はチームを組むわけでなく、一定期間の間に有志が個人で生成系AIに関連した開発を行い、LTを行うという形。
合計6名のエンジニアがLTをしてくれたので、1記事につき1つ、そのレポートをお届けします!(シリーズ記事になります)
イベント概要
どんなハッカソンなのかを簡単に説明する&今後社内イベントを企画する方の参考に、開催概要と社内展開情報を公開しておきます。
【テーマ】生成系AI活用について
開催日時:5月2日 17:00-19:00
場所 :Synamonオフィス(オンラインでの参加も可)
申し込み期限:4/28 16:00【概要】
- Synamonのエンジニア主体で任意社内ハッカソンを行う
- 【背景】新規事業を見据えたモックアプリ開発となると事業計画など、足が重くなる可能性が高いので、一旦スピード感を重視する
- 事業化は考慮せずに、生成系AIを活用して、何か面白いことができないかを考えて、各自が作ってきたものを5/2に発表する
- Activ8の人も巻き込んで参加したい人を募る
【概要】
- あくまで参加は任意でOK
- 本業に支障が出ない範囲で各自取り組みをしてもらう
- メインは平日夜や土日などを使うイメージだが、本業が早く終われば業務時間内の一部を使って進めるのはOK
- テーマは自由だが、業務効率の改善やAI配信事業などに関連するものだと嬉しい
- APIの利用などは各自のアカウントで実施する(今回は自己負担)
- 動作は各自のローカル環境で動くものがあればOK
- 社内用途なので、最悪動作が一部バグっていても問題なし
- 1人10分程度で作ったものを見せて、参加者からの質疑応答などを行う
- 今回は表彰などは行わないが、終わった後に美味しいご飯とお酒を出す場を用意する
- 発表会の様子やアウトプットをテックブログにも載せるかも
- 各自の記事で詳細を共有するなどもOK
- 出てきたもので、既存業務や新規事業に活かせそうなものは、取り込む可能性もあり
「SentenceBERTを使って「草」や動画チャットのコメントの特徴を追ってみた」 - 松原
 発表第一弾はエンジニアの松原(@blkcatman)です。
発表第一弾はエンジニアの松原(@blkcatman)です。
ハッカソンテーマは「生成系AI」なのですが、今回はその前段となるデータ分析手法について発表をしていただきました!
特徴量(スペックのような概念。ものを説明するときに特徴をカテゴリ分けして表すもの)とBERT(人力では特定の難しい特徴量。機械学習においてはベクトルの多次元データで表現される)についての軽い説明の後、コメントのベクトル化についても説明いただきました。


実際にYouTubeに上がっている動画を4つ使用し、チャットのコメントをBERTでベクトル化すると、その次元数はなんと768次元に。
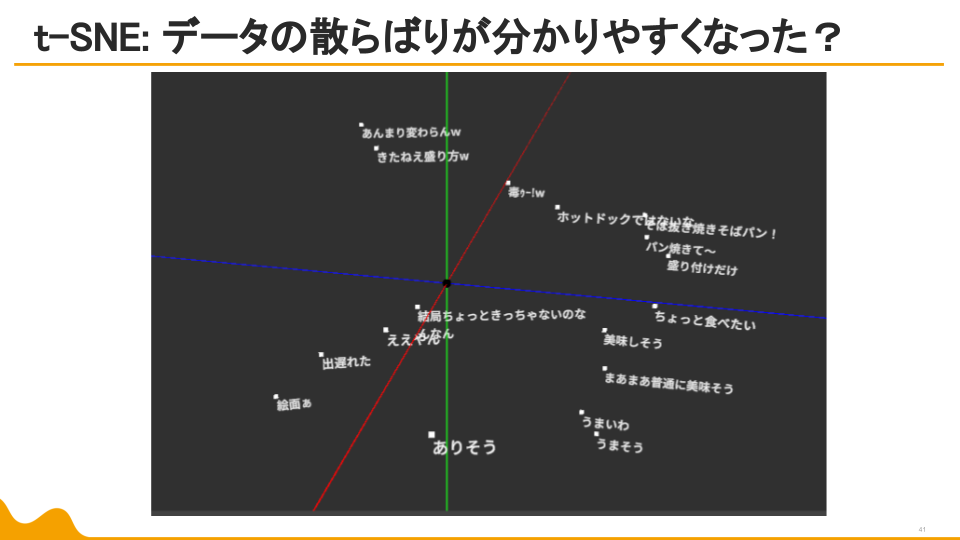
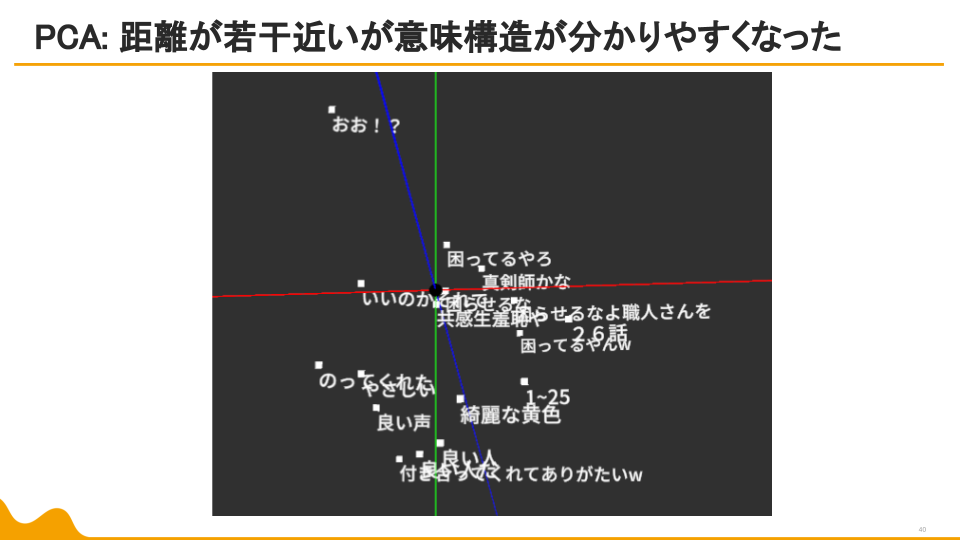
目視で確認していくのは流石に無理なので、PCA(主成分分析。線形関係の有無を調べるの向き)とt-SNE(データをいくつかの集まりに分解するための有効手段)を使って、768次元のベクトルを3次元ベクトルに変換してベクトルを分析していくことにします。
松原さんは以下の二つの仮説を立てましたが…?
仮説1:動画チャットだとある程度似たようなコメントがついてるので、ベクトル自体が似たような構造を持っているのではないか? (似たような意味であれば位置が近い≒近傍する)
仮説2: ベクトルの各要素に多変量解析的な線形(または非線形)関係が無くても、ベクトルが示す位置関係で意味構造を示せるのではないか?
結果


草か、NOT草かがまず第一主成分として現れてきました!!!これは流石に草。
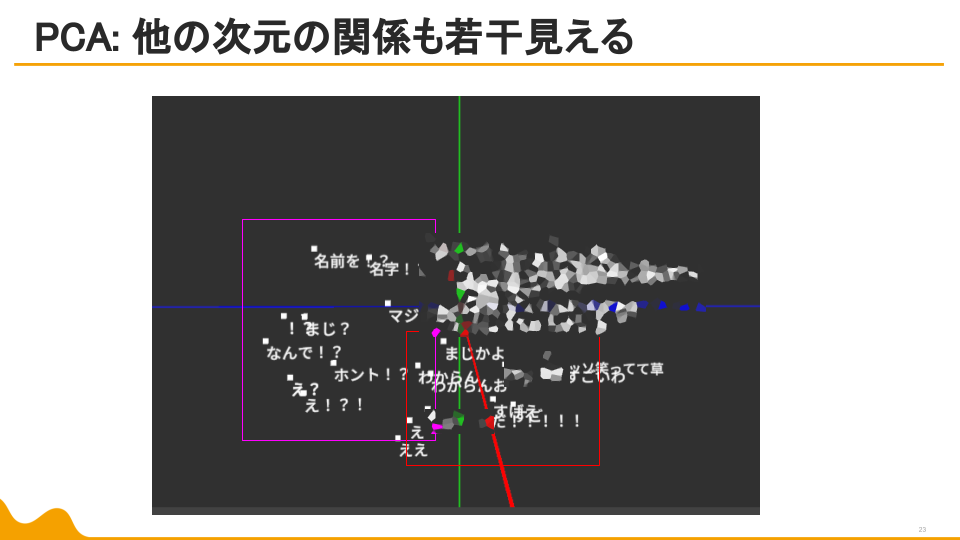
他の次元の関係も若干ですがわかります。一方t-SNEはというと…
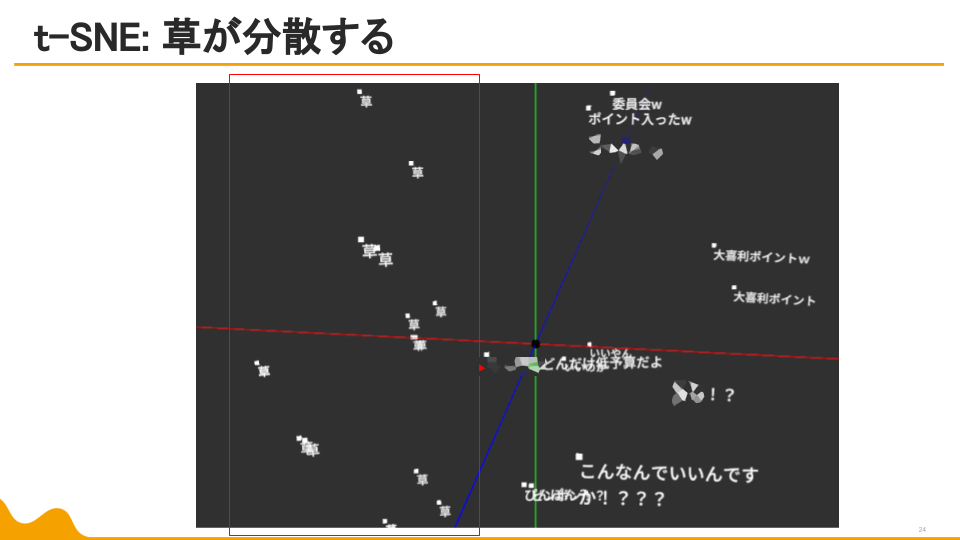
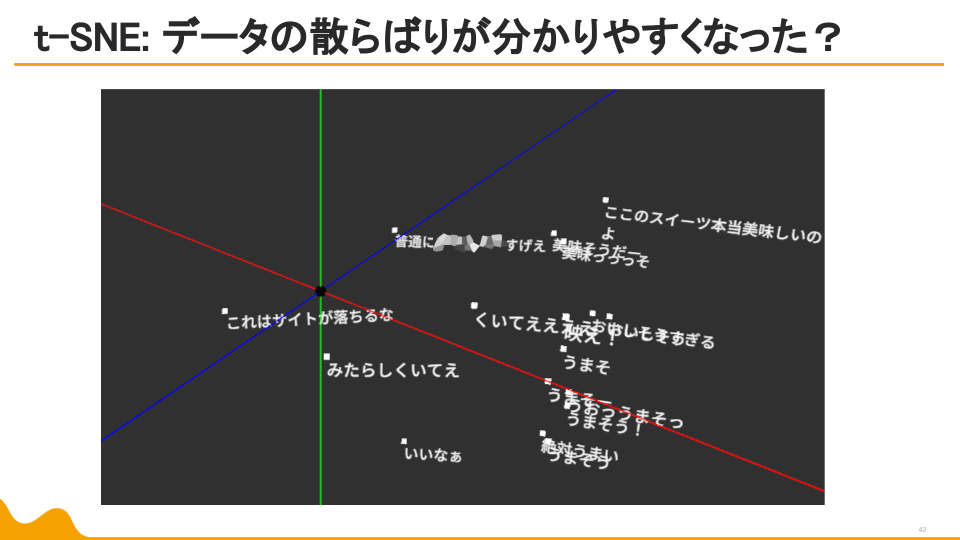
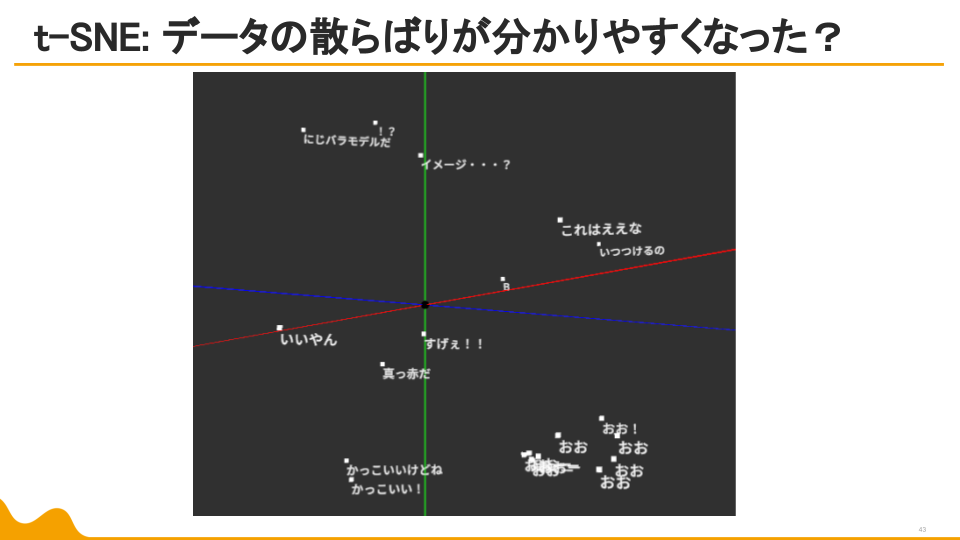
草の分散が発生。
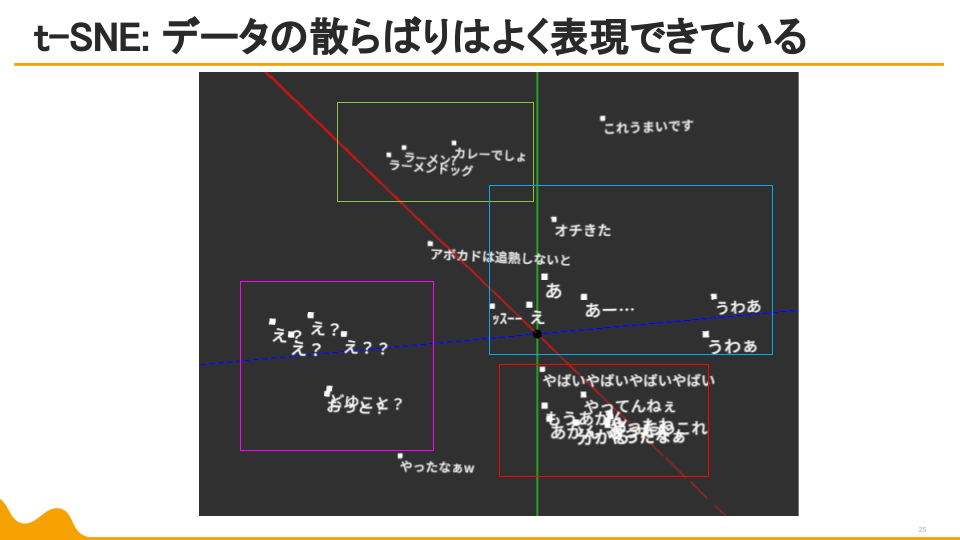
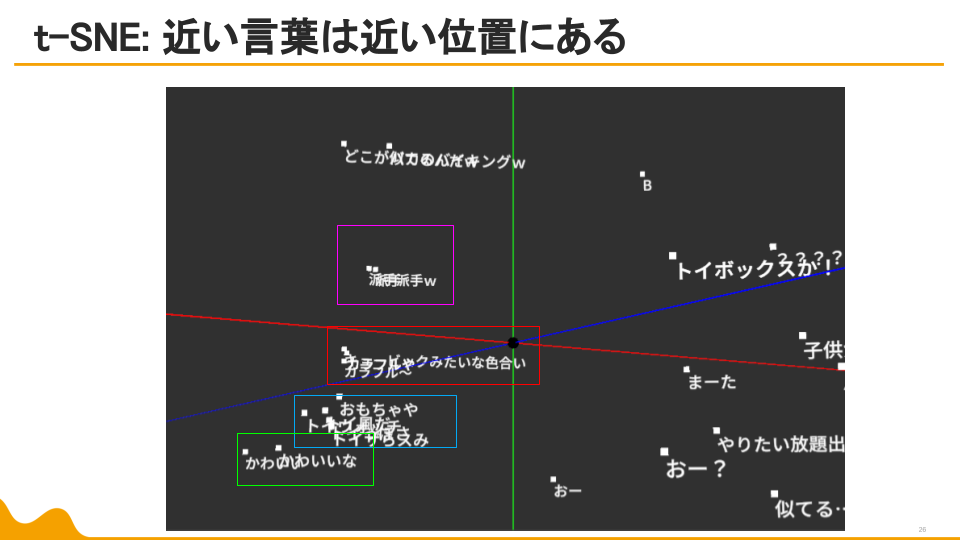
しかし、データの散らばり方や、似た属性の言葉の位置感は非常にわかりやすい結果に。
この後は、「草」を分析対象から除外して再度分析。
第一主成分の寄与率は大きく減ったものの、「草」以外のデータが誤差としてみなされる傾向は取り除けました。


まとめ
今回は、SentenceBERTを使って動画チャットのコメントをベクトル化→高次元ベクトルをPCA、t-SNEを利用して低次元のベクトルに変換→Unity上で時系列を追いながらコメントの傾向を3Dグラフから分析→‘草’ コメントを除外してデータを再分析までを発表していただきました。
結果として時系列ごとのコメントの特徴や、登場するワードの傾向は読み取れた&特定のキーワード(今回は‘草’ )がベクトル化した文章のデータ構造に強く干渉する可能性があることが分かったとのこと。
今後は友好的なユーザーコメントの傾向を分析して、配信者が行う特定イベント時(配信者の発言など)に自動的に応答するBOTを作ったり、3次元までデータを落とさずに、可視化・分析する手法について調べたいということで、次回以降も楽しみです!