株式会社Synamonのエンジニアの岡村です。自分はGitHub Actionsを使ったCIをよく弄っているのですが、先日、とある事情からCIで作成された成果物をNASサーバーにアップロードする必要が出てきたので、それに対応するために、ftpプロトコルで成果物をアップロードするGitHub Actionを作成してみました。既存のActionのフォークとはいえ、きちんと体裁の整ったActionを作るのは初めてだったのと、思っていたより簡単に作れたので、せっかくだから記事にしてみる事にしました。 GitHub Actionsでは、作成された成果物は、基本的に公式の用意しているupload-artifactアクションでアップロードされます。
アップロードしたものはGitHubが用意したオンラインストレージ上に保存され、保存された成果物は実行の要約ページ上にある成果物一覧に表示されて、ダウンロードする事が出来るようになります。 ただし、GitHubが用意したオンラインストレージには といった制約があります。 諸事情により、今回のケースでは以前作成したAWS環境や、s3を含むクラウドストレージの使用が出来なかった為、代替手段として(オンプレでRunnerを走らせていたのもあり、)同じLAN内にあるNASサーバーへのアップロードを実施することにしました。 NASサーバーはSynology製で、アップロード手段は色々用意されていました。最初はネットワークストレージのマウントや公式の提供しているAPIでのアップロードを検討したのですが、 であったため、枯れて安定した技術であるFTPを使ったアップロードを試してみる事にしました。 最初は直接curlコマンドでアップロードを行っていたのですが、すぐにそれでは機能が足りないことに気づきました。 curlやzipを駆使して出来ないこともないのですが、ステップ数が多くなってしまいyamlファイルの可読性が下がり、メンテナンスもし辛くなってしまいます。 そこで、以前s3へのアップロード周りでMarketplace製のActionを使っていた経験から、ftpを使って成果物をアップロードできるActionも転がっているのではないかと探してみました。ところが、ftpによるデプロイActionは幾つか見つかったのですが、純粋にupload-artifactのftp版となるようなActionはまだ存在していないようでした。 そのため、GitHubが公式で提供しているActionであるupload-artifact及びdownload-artifactをフォークし、アップロード処理のみをftpで実装したカスタムActionの作成を試してみることにしました。 作成したものがこちらです。 upload版とdownload版を両方作りました。作り自体は単純で、それぞれのオリジナルのActionの内部で使われているArtifactClientインターフェースを実現するftp-artifact-clientを実装しただけです。公式の実装できちんとインターフェースが区切られていたので、その中でもそれぞれのaction内で使用されているメソッドを実装し、テストも作成しています。 あとは、ftpサーバーに接続するためのアドレスやID, パスワード等のパラメータを露出させて実装は完了です。 入力がupload-artifact及びdownload-artifactの仕様に沿っているので学習コストが滅茶苦茶少ないです。エンドポイントやユーザー情報が一致していればuploadした成果物を別のjobでdownloadして再利用する事も可能です。nodejs製でプラットフォーム間の互換も(多分)あります*3。既存のツールと同じように扱えるのは正義ですね。 今後の課題としては、多少効率が悪い箇所があるのでその最適化と、元のupload/download-artifactが更新された時にどの程度追従できるか/するべきかという所でしょうか。なるべく安定していてほしい…… せっかくなのMarketplaceに公開してみました。GitHub公式のドキュメントを読めば簡単に公開することが出来ます。 npmのパッケージ詳細ページと異なり、GitHub Marketplaceの詳細ページ上ではこのActionがどの程度利用されているのか確認できないのがちょっとさみしいですね。 GitHub ActionsでローカルのRunnerからNASにアップロードする為にupload-artifactをフォークしたftp-upload-artifactアクションを作りました。GitHub Actionsは他のCIツールに比べるとまだ若く、ニッチなニーズを満たすようなActionは見つからないこともありますが、簡単にActionを作成できるし利用できるので、「なければ作ればいいじゃない」がとてもやりやすい仕組みになっているように感じました。ftp以外のプロトコルでupload-artifactするActionもその気になれば簡単に作れそうです。 *1:GitHubは$0.25/GB、s3はap-northeast-1のstandardクラスで0.025$/GB。2023年4月9日時点 *2:https://docs.github.com/ja/actions/learn-github-actions/usage-limits-billing-and-administration#artifact-and-log-retention-policy *3:windowsとmac上で動作を確認済
はじめに
GitHub ActionsとNASへのアップロード
アップロード方法の検討
公式upload-artifactアクションのカスタマイズ
フォークしたupload-artifactアクションの実装
自作したActionの感想
GitHub Marketplaceへの公開
まとめ
LangChainをLocalのDockerで動かしてみる

こんにちは、エンジニアリングマネージャーの渡辺(@mochi_neko_7)です。
最近常に話題になっているChatGPTを始めとするLLM(Large Language Model)ですが、APIを利用して単にChat(正確にはChat Completion)をする以外に少し凝ったことをしたいというケースも多いでしょう。
そのような場合に便利なLangChainというPythonライブラリがあります。
概要はこちらの記事などでも紹介されています。
今回はタイトルにもあるように、このLangChainをLocalのDocker環境で動くようにしてみたいと思います。
モチベーション
Dockerを使うメリットは改めてここで語るまでもないと思いますが、個人的にはPythonのパッケージ毎のPythonバージョンの互換性で何度か大変な思いをしたこともあり、Pythonを使うときは可能ならDockerを使いたいと思っていました。
普段からPythonを触っているというわけでもないので、正直あまり詳しいわけではないです。
今回初めて触ったPoetryというパッケージマネージャーにはPython環境の仮想化の機能もあるみたいなので、考えすぎかもしれません。
最終的にどこかのクラウド環境にホスティングすることを考えるとDockerで環境構築しておいた方が移植しやすいので無駄ではないでしょう。
環境
- macOS
13.3.1, ARM64(M2) - LangChain
0.0.135 - Docker Desktop
4.13.0 - Python
3.9 - Poetry
1.4.2
前提
前提、というか自分の知識レベルは下記になります。
- Pythonは触れる
- OpenAIのChatGPTのAPIは触れる
- Dockerでのローカル環境構築は分かる
- Poetry、LangChainは触ったことない
全て詳細に説明するのは流石に大変なので、Docker、Poetry、LangChainの最低限のセットアップをメインに解説していきます。
Docker環境のセットアップ
セットアップの手順を順番に説明していきます。
ソースはこちらに置いています。
もしこれをそのまま触る場合は、ご自身のOpenAIのAPI Keyを発行して、.envの環境変数ファイルに書いて配置する必要があることに注意してください。
フォルダ構成
ここではフォルダ構成を次のようにします。
.
├── compose.yaml
└── langchain
├── Dockerfile
├── .env
├── (poetry.lock)
├── (pyproject.toml)
└── src
└── main.py
poetry.lockとpyproject.tomlのファイルは後でPoetryのプロジェクトを作成して生成するため、初めから置いておく必要はありません。
compose.yaml
先日の弊社テックブログの記事に倣って、compose.yamlを作成します。
services: langchain: build: context: ./langchain dockerfile: Dockerfile tty: true ports: - 8000:8000 volumes: - ./langchain:/app env_file: - ./langchain/.env
今回はLnagChainだけのシンプルな構成なので特に迷うところはありませんが、ポイントはenv_fileで環境変数を指定しているところでしょうか。
OpenAIのAPIを利用するために必要なOPENAI_API_KEYはこの環境変数ファイル.envに置いておき、このファイルは.gitignoreに登録しておき、GitHubに上げても他の人に自分のAPI Keyを利用されないようにしておきます。
OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Dockerfile
FROM --platform=arm64 python:3.9 RUN apt-get -y update WORKDIR /app RUN pip install poetry ## COPY pyproject.toml poetry.lock ./ ## RUN poetry install --no-root COPY . .
今回はCLIで触るだけなのでPythonの公式ImageにPoetryを追加するだけの最低限のセットアップのみで、##でコメントアウトしてあるところはPoetryプロジェクト作成後に使用するものです。
先頭の--platform=arm64は自分がmacOSのARM64版を使用しているための事故防止です。
Pythonのバージョンは深く考えていませんがとりあえず3.9では問題なく動いています。
上記のセットアップをした後、通常通りDockerでbuild&upし、exceコマンドでbashを立ち上げます。
$ docker compose up -d --build $ docker compose exec langchain bash
Poetryプロジェクトのセットアップ
今回はPoetryを使用してLangChainを触る環境を作成します。
Poetryプロジェクトの作成
PoetryのインストールはDockefileに記述しているため操作は不要ですが、ちゃんとインストールされてPathが通っていることを確認します。
$ poetry --version
Poetryのプロジェクトの作成方法はこちらなどをご覧ください。
自分は最低限のファイルだけinitコマンドで作成しました。
$ poetry init
完了するとpyproject.tomlというTOML形式のプロジェクトファイルが作成されます。
[tool.poetry]
name = "langchain-docker"
version = "0.1.0"
description = ""
authors = ["Mochineko"]
license = "MIT"
readme = "README.md"
packages = [{include = "langchain_docker"}]
[tool.poetry.dependencies]
python = "^3.9"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
その後、次のコマンドでプロジェクトの初期化を行い、poetry.lockファイルが作成されます。
$ poetry install --no-root
--no-rootのコマンドはpyproject.tomlのpackages = [{include = "langchain_docker"}]のオプションで自身のPackageを追加しようとしてエラーが出るのを回避するためですが、自分もPoetryに慣れていないのであまり詳しくありません。
必要なPackageの追加
上記のpyproject.tomlにはまだ何もPackageの依存関係がないため、LangChainを動かすために最低限必要な次の2つのPackageの依存関係を追加します。
langchainopenai
コマンドはpoetry addを使用します。
$ poetry add langchain $ poetry add openai
実行後、pyproject.tomlに依存関係が追加されていることを確認してください。
[tool.poetry.dependencies] python = "^3.9" langchain = "^0.0.135" openai = "^0.27.4"
これで最低限のPoetryプロジェクトのセットアップは完了です。
動作確認
Dockerfileの##のコメントアウトを外して、再度Dockerのビルドをしてbashを開きます。
Docker内のCLIで、まずPoetryのCLIを立ち上げます。
$ poetry shell
すると仮想環境で先ほどセットアップしたPoetryプロジェクトが使用できるようになるようです。
クイックスタートの記事を参考に、LLMをシンプルに動かす適当なPythonスクリプトを作成します。
from langchain.llms import OpenAI # LLMの準備 llm = OpenAI(temperature=0.9) # LLMの呼び出し print(llm("コンピュータゲームを作る日本語の新会社名をを1つ提案してください"))
このファイル名をmain.pyとして、srcのディレクトリに移動してからこれを実行してみます。
$ python main.py
するとLLMに渡した"コンピュータゲームを作る日本語の新会社名をを1つ提案してください"に対する回答がprint関数によってCLIに表示されると思います。
正しく結果が表示されれば、LangChainが動いていることが確認できたことになります。
ちなみに、LangChainの色々な機能を触っていると追加でPackageが必要になることもあると思いますが、その場合もpoetry addで必要な依存関係を追加していくだけ問題ないです。
まとめ
上記で紹介した手順で、LocalのDocker環境でLangChainを実際に動かすことができました。
それほど凝ったことはしていませんが、いくつか注意すべきポイントを挙げておきます。
- OpenAIのAPI Keyはcompose.yamlで外から環境変数ファイルとして設定しておき、ハードコーディングしない
- Poetryの
initコマンドで自身のプロジェクトを読み込むのに失敗していたら--no-rootオプションで解決できるかもしれない - PoetryでPythonスクリプトを実行する前に一度
poetry shellで仮想環境を立ち上げる
おわりに
ここまでおおよそ2時間くらいでLangChainをLocalのDockerで動かすためのセットアップができました。
その後はドキュメントを読んでずっと気になっていたKnowledge Graph MemoryやIndexなども少し触ってみましたが、自分で実装するにはそれなりに大変そうな機能がサクッと利用できるようになっていてとても便利ですね。
LangChainと似たようなコンセプトでMicrosoftもSemantic Kernelを公開していますし、こういったLLMのミドルウェア的なものは増えていくのではないでしょうか。
今回はLangChainを動かすところまでに留めましたが、今後はFastAPIを使ってLangChainAPI Server化して他のアプリケーションからLangChainの機能を利用することなども試してみたいなと思っています。
React Docsの「You Might Not Need an Effect」をしっかり理解する

こんにちは、フロントエンドエンジニアの堀江(@nandemo_3_)です。
だいぶ時間がたってしましましたが、 Reactのドキュメントが一時、Twitterで話題になりました。
話題となったドキュメントはこちらです。
タイトル「You Might Not Need an Effect」は、
人によって、「Effectは不要」や「非推奨」という言い回しをされており、 今まで多用していたEffectが使えなくなることに、驚きを隠せませんでした。
そして、ちゃんとドキュメントを読むと、語弊があるなと思いましたので、解説がてら紹介します。
You Might Not Need an Effectの意味とは
まず、冒頭の説明について。

こちらを要約すると、
外部システムが関係しない場合は、Effectを必要としない場合があります。 不必要なEffectを削除することで、コードを追跡しやすく、実行速度を上げ、エラーが少なくなります。 つまり、ReactではEffectを使用することは重要ですが、外部システムに関与しない場合は、不要なEffectを避けることが重要です。
となります。
場合によってEffectは不要ということなので、
「Effectは不要」や「非推奨」だけでは、人によって解釈が変わってしまうので、注意が必要ですね。
2つの要点
このドキュメントで、まず語られていることは、2つあります。
1つ目のケース
1つ目のケースは、レンダリング用にデータを変換するためにEffectは不要というものです。
ドキュメントでは、ステート単体で完結するフィルタリングや表示形式の変換などは、Effectを使用せずにレンダリング時に行うと良いと言っています。
例えば、propsで受け取ったlistを昇順にソートするサンプルコードがあるとします。
function SortList({ list }) { const [newList, setNewList] = useState([]); useEffect(() => { setNewList(list.sort((a,b) => a + b)) }, [list]); // ... }
Effectを使わず、このように書くことができます。
function SortList({ list }) { const newList = list.sort((a,b) => a + b) // ... }
Effectはしばしば、初期表示の処理やステート更新時の処理を書くことがありますが、
旧ステートでレンダリング
ReactがDOMを更新
Effectを実行
再レンダリング
という順番で処理されるため、 1回目のレンダリングで処理をまとめることで、余計なレンダリングを抑えられます。
そのため、APIが絡まないステート単体の処理などは、Effectを使用せず、関数のトップに書くのが最適解ということが分かりました。
2つ目のケース
2つ目のケースは、ユーザーイベントを処理するためにEffectは必要ないというものです。
ドキュメントでは、商品を購入したときに通知を表示する場合、Effectを使うよりも、購入ボタンのクリックイベントハンドラーで処理する方が適切と言っています。
例えば、プロフィールの新規作成と変更ができるボタンがあり、そのイベントごとにスナックバーを表示するサンプルコードがあるとします。
function Profile({ firstName, lastName }) { const [profile, setProfile] = useState(null); const [showSnackBar, setShowSnackBar] = useState(""); useEffect(() => { if (profile !== null) { showSnackBar(`Update Profile.`); } }, [profile]); function handleNewClick() { setProfile({ firstName, lastName }); } function handleEditClick() { setProfile({ firstName, lastName }); } // ... }
上記のソースは、profileがnullでない場合、常にスナックバーが表示されてしまう問題があります。
以下のように関数化することで、問題が解決されます。
function Profile({ firstName, lastName }) { const [profile, setProfile] = useState(null); const [showSnackBar, setShowSnackBar] = useState(""); function updateProfile { setProfile({ firstName, lastName }); showSnackBar(`Update Profile.`); } function handleNewClick() { updateProfile() } function handleEditClick() { updateProfile() } // ... }
このサンプルコード以外にも、原文にはたくさんのユースケースがありますので、ぜひ一読ください。
Effectの問題
Effectには問題があるようです。
Effectは、レンダリング後に処理が実行されます。
つまり、Effectがあると必ず2回以上処理されるということです。これは、実行処理的に効率が悪いです。
例え遅くなかったとしても、コードを追加していったときに、何度もレンダリングされることによる弊害が生まれる可能性もあります。
また、Effectはクライアント側で処理されます。これは、特にSSRを使っている場合に問題となります。
部分的にはSSRとCSRが混在するため、非効率です。(もちろんクライアント側で処理させたいという意図がある場合は、問題ないと思います)
おそらくこのドキュメントの作成意図や背景には、こういった文脈があるのではないかと思いました。
まとめ
最後まで、読んでくださりありがとうございます。
自分は、Effectが非推奨と知った時は、え!使っちゃダメなの?過去から現在まで多用してたんだけどどうすればいいの!?と不安になりました。
しかし、そんなことはなく、適切にEffectを理解し、最適な場所で使うことで、リーダブルなコードになり、実行速度、品質が向上するという内容でした。
正直、ドキュメントのサンプルコードを見て当たり前だと感じつつも、過去に不必要にEffectを使っていたと思うので、自省の念を込めて記事を書きました。
そして、最も信頼できる情報源である原文を読んで、自分で判断することが大切だと思いました。 つまり、この記事も参考にする程度で留めておくことを、お勧めします。
Unityに最適化した音声デコードライブラリを自作する上で工夫したこと

こんにちは、エンジニアリングマネージャーの渡辺(@mochi_neko_7)です。
今回はUnityで音声データをランタイムでデコード/エンコードするライブラリを作った話を紹介します。
先日、OpenAIのChatGPTやWhisperをWebAPIで利用できるようにする話を記事で紹介しました。
この延長として、ChatGPTで生成した会話をVOICEVOXやCOEIROINK、Koeiromapなどの音声合成サービスに渡して音声化をしていました。
こういったUnityの外側との音声データのやり取りをする際には、どうしてもランタイムでの音声データの変換処理をする必要が出てきます。
その際に手軽に利用できるライブラリを趣味で開発しました。
こちらの紹介を簡単にしつつ、Unityにおける実装の工夫や使用リソースの最適化などのポイントに関しても紹介します。
メインスレッドの処理負荷、メモリ負荷をそれなりに抑えるよう作っているため、手軽に利用しやすいのではと思っています
基本的な内容ではありますが、重い処理をするライブラリをUnity向けに作成する際にも参考になれば幸いです。
想定しているユースケースと背景
例えば音声合成だと、テキストから音声データを生成し、WebAPIで特定のフォーマットのバイナリーデータとして受け取り、それをデコードして波形のサンプルデータにしてからAudioClipにデータをセットして利用します。
Whisperなどの音声認識だと逆で、Unityで録音した音声データを特定のフォーマットにエンコードして、WebAPIにアップロードをしてテキスト化を行います。
データの流れとしては下記のようになります。
Unity ⇆ AudioClip ⇆ Audio Codec (WAVなど) ⇆ Binary ⇆ 外部サービス
しばらく前にUnityでの画像のデコードの記事も書きましたが、Unityは標準では画像や音声、動画などのメディアファイルのエンコード/デコードはサポートしていない or 使いづらいです。
かといって音声ファイルの処理のためだけに大きな音声系ライブラリを導入するのも少し重たいですよね。
UPMでサッと導入でき、Unityに最適化されていて取り回しの良いライブラリが欲しいと思い、自作することにしました。
現在はすぐに使用したかったWAVのデコード/エンコードのみ対応していますが、後日MP3の対応も追加するつもりです。
実際に使ってみたい方はREADMEに書かれているPackage参照をmanifest.jsonに追加してください。
使い方
使い方はシンプルなので、サンプルかテストコードを見ていただければ分かると思いますが、簡単に説明します。
WAVファイルのデコードをしたい場合には、データの Stream とファイル名、それから CancellationToken を WaveDecoder.DecodeByBlockAsync に渡して await すると、デコードされた音声データが AudioClip に加工されて取得できる、といった形です。
audioClip = await WaveDecoder.DecodeByBlockAsync(
stream,
fileName,
cancellationToken);
WAVファイルのエンコードの場合は、エンコード結果を書き込みたい Stream を用意して、エンコードしたい音声の AudioClip と CancellationToken と共に WaveEncoder.EncodeByBlockAsync に渡して await する、という形です。
await WaveEncoder.EncodeByBlockAsync(
outStream,
audioClip,
cancellationToken);
例えばファイルに書き込みたい場合はWriteModeの FileStream を指定すればよいですし、WebAPIでPOSTするなど他で使いたい場合は MemoryStream でもよいです。
こちらやこちらでは実際に使用もしていますので参考になるかも知れません。
利用している3rd Partyライブラリ
自作したといっても0から作成したわけではありません。
C#(.NET)にはNAudioという有名な音声ライブラリがあるため、これを利用します。
サンプルを眺めると様々なコーデックに対応した汎用的なAPIもあるように見えますが、Core以外ではMediaFoundationを利用する実装も含まれていて、それだとWindowsでしか動かなくなってしまいます。
そのため、WAVやMP3といったよく使うコーデックはちゃんとサポートしているNAudio.Core部分のみ利用し、コーデック別の対応を自分で行うことにします。
ちなみに対応しているWAVファイルは今回はLinear PCM、bit数は16bit、24bit、32bit、IEEE floatのみで、μ-law、a-lawにはまだ対応していませんのでご注意ください(あまり使用しないとは思いますが)。
また、下記で紹介するマルチスレッドの最適化の都合でUniTaskも利用しています。
実装上の工夫
Unityで音声データなどのメディアファイルを取り扱う上で気をつけたいことはまず2点あります。
- 処理負荷:デコード/エンコードには通常それなりの処理時間がかかること
- 短い音声ファイルでもコーデックによってはそれなりに、長い音声ファイルでは言うまでもなく
- メモリ負荷:デコード/エンコード時にはメモリを食いやすいこと
- 大きいデータを愚直に配列として変換しているとメモリ消費が大きくなりやすいため、なるべく効率よく処理をしたい
処理負荷対策
1の処理負荷対策としては、なるべくThread Poolでデコード/エンコード処理を実行して、UnityのMain Threadでの処理負荷を減らす、というのが基本となります。
Main Threadでの処理が重いと、UnityのUpdateの処理が詰まってしまいFPSの低下に繋がります。
アプリの動作がカクつくとユーザー体験の質が下がりますし、VRなどではVR酔いにも繋がるため可能な限りケアしておきたいポイントになります。
NAudioを使ってデコード/エンコード処理自体はPure C#で書かれているためそのままThread Poolに投げれば良いだけですが、AudioClipなどUnity上のオブジェクトとのデータのやり取りをする部分はMain Threadでしか実行できません。
UniTaskではThreadを明示的に切り替えるAPIが用意されているため、これを利用します。
// Main Thread await UniTask.SwitchToThreadPool(); // Thread Pool // 思いデコード処理をここでやる await UniTask.SwitchToMainThread(cancellationToken); // Main Thread // AudioClipなどの操作はここでやる
このようなThreadの切り替えをして重い処理をなるべくThread Poolで処理することで、Main Threadでの処理負荷を最適化します。
メモリ負荷対策
次に2のメモリ負荷の対策も考えます。
メモリも言うまでもなくなるべく使用量が小さい方が良いですし、特にAndroid/iOSなどのモバイル端末で動かす場合には使用できるメモリの制約も大きいため、こちらもなるべくケアしておきたいポイントになります。
例えば下記の音声データがあると仮定します。
- WAV
- 5MB
- 16bit PCM
- 44100Hz
- ステレオ(2ch)
このデータを扱うときにどれくらいのメモリ消費があるのか計算してみましょう。
- サンプルあたりのbyte数は16bit PCMなので16 bits = 2 bytes
- 5 MB = 5 * 10242 bytesをWAVのヘッダーの部分は無視してざっくり5 * 10242 / 2 サンプル数
- サンプルは32 bit (4bytes) floatに変換するので、(5 * 10242 / 2) * 4 = 10 * 10242 = 10 MBの配列のメモリが必要
- バイナリーデータ本体、デコードしたfloat配列、AudioClip側のデータがあるので、合計 5 + 10 * 2 = 25 MB
おおよそ元のデータの5倍とそれなりの大きさになります。
ちなみにこのサイズだとざっくり30秒くらいの音声でしょうか。*1
ではどこが改善できるのかという話ですが、大本のデータはStreamにしておけば呼び出し側で一定改善できますが、AudioClipの部分はUnityの圧縮形式がランタイムでは使用できないことを考えると改善は大変そうです。
一方、まとめてデコードするのではなく一定の長さのfloat配列をバッファとして利用し、少しずつデコードしてAudioClipに書き込むという手法を取れば、中間のサンプルデータで使用するメモリ量を改善できる余地があります。
音声データの単位はコーデックによって異なりますが、WAVはサンプル×チャネル数が最小単位で、NAudionにはこれを読み出すAPIが用意されています。
ただし、この最小単位毎にデコード→AudioClip書き込みをしようとするとサンプルの数自体がとても多いので、Threadの切り替えの処理がオーバーヘッドとなってしまいます。
そのため、一定サイズのバッファのサンプル分をまとめてデコードすることを繰り返す方法を取ることで、メモリ負荷をバッファ分に抑えつつ、Thread切り替えの回数を減らす、といった対策を取ることができます。
実際の実装はこちらで、呼び出し側で用意した一定サイズのサンプル = Blockを使い回しているのがわかると思います。
こういった工夫を取ることで、メモリ負荷と処理負荷のバランスを取ることができます。
まとめ
以上の実装上の工夫をまとめると下記になります。
- 重いデコード/エンコード処理はなるべくThread Poolで実行するようにして、Main Threadへの処理負荷を抑える
- 変換における中間データはバッファを使い回すようにしてメモリ負荷を抑える
- 音声データはサンプルの塊ごとに処理を行うことで、Thread切り替えの処理負荷とメモリ負荷のバランスを取る
上記の説明はWAVのデコードを例に取りましたが、エンコードする際もほぼ同様です。
工夫の観点自体は基本的な内容ですので、他のUnity向けのライブラリなどを作成される際にも参考になればと思います。
今後の発展
まだ直近欲しかったWAVのデコード/エンコードしか実装していませんが、NLayerを使えばMP3のデコードも比較的簡単に実装できますので、今後対応したいと思っています。
MP3のエンコードはまだ試したことがないので調べるところからになります。
μ-lawやa-lawのWAVもNAudioに対応があるので対応できるとは思いますが、需要はあるんですかね?
また、今回は手軽さからNAudioを採用しましたが、パフォーマンスだけを考えればC++やRustなどで書いたネイティブプラグインを導入する方が良いでしょう。
対応プラットフォームをちゃんと考える必要があるため少し腰が重いですが、ChatGPTを利用したリアルタイムな対話をする上ではいずれレイテンシが気になって対応をするかもしれません。
おわりに
今回はシンプルなWAVファイルのデコードを中心に話をしましたが、ライブラリ開発の全体の流れをざっと見返すと、
- WAVフォーマットへの対応部分はNAudioに任せる
- Threadの取り扱いはUniTaskを利用する
- その上でUnityで使用するにあたっての処理負荷・メモリ負荷を抑えるためのちょっとした工夫を入れる
- 最終的にはStream ⇆ AudioClipで変換できるUnityで利用しやすいAPIにして提供する
といった形になります。
やっていること自体はそれほど難しい内容ではありませんが、取り回しの良い小さいライブラリができると自分でも再利用しやすいですし、もしかしたら他の方にも利用してもらえるかも知れません。
自分が使いたいというモチベーションで開発したライブラリではありますが、もし他にも使ってくださる方がいたらフィードバックや要望なども大歓迎です!
*1:5 * 10242 / 2 / 2(ch) / 44100(Hz) ~= 30s
ServerlessFrameworkを使ってChatGPT APIを使ったLineBotを作る
はじめに
こんにちは、エンジニアのクロ(@kro96_xr)です。
最近、5年くらい前にQiitaで書いた記事にちょこちょこいいねをいただくんですよね。
なぜ今更この記事を見てもらえているんだろうと考えていたところ、ChatGPT APIを用いたLineBotの作成に取り組んでいる人がいるのではないかと思いました。というわけで私も試してみることにしました。
二番煎じどころではありませんが、自身の体験を共有することで皆さんの参考になればと思います!
なお、今回検証したコードは、以下のリポジトリにまとめています。
※先にお詫びです
記事を書きながらも検証しているのですが、時間帯によってはタイムアウトでLambdaの処理が終了します。
ログを見ているとAPIレスポンスが時間内に返ってこないようでした。
Lambdaのタイムアウト値はAPI Gatewayの制約内で最大にしているので、安定運用のためには対応を考える必要がありそうです。
ブラウザ版でも重いことがあるため仕方ないのかもしれませんね…
実装結果
まず、この記事で実装したBotのデモになります。以下のスクリーンショットをご覧ください。

ChatGPTのように会話の流れを理解してくれていますね。
構成
当初は、過去に実装したLineBotと同様にHeroku上にFlaskで実装しようかと考えていました。
しかし、ChatGPTとは異なり、API単体では文脈を覚えることができないため、メッセージを保存しておくデータストアが必要でした。
そのため、今回は以下の構成を採用することにしました。
構成の検討にあたり、Classmethodさんの記事を参考にさせていただきました。いつもありがとうございます。
- API Gateway
- Lambda
- DynamoDB
構成を図示すると、以下のようになります。
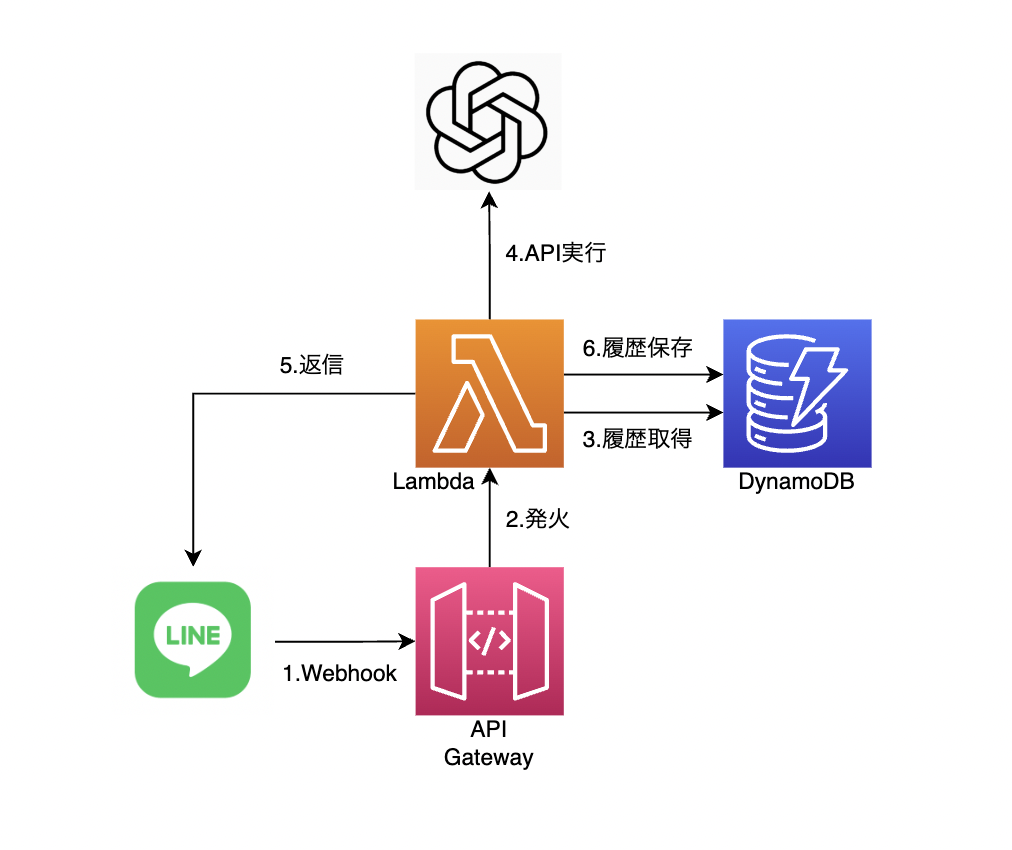
なお、Lambdaのランタイムは過去と同様Pythonでやっていきます。
実装
ここからは、実際の実装について見ていきます。ちなみに、この辺りもChatGPTと一緒に開発しています。
ディレクトリ構成
ディレクトリ構成は、以下のようになっています。
. ├── .env ├── handler.py ├── requirements.txt └── serverless.yml
環境変数
まず環境変数にAPIキーなどの情報を設定します。
OPENAI_API_KEY= LINE_CHANNEL_SECRET= LINE_CHANNEL_ACCESS_TOKEN= DYNAMODB_TABLE=
インフラ構築
次に、インフラ構築をServerless Frameworkを使用して行います。
serverless-python-requirements プラグインを使っているため、事前にインストールしてください。
sls plugin install -n serverless-python-requirements
serverless.ymlは以下のようになります。
service: openai-line-bot frameworkVersion: '3' useDotenv: true # カスタム変数 custom: defaultStage: dev pythonRequirements: dockerizePip: non-linux # プロバイダ provider: name: aws runtime: python3.9 timeout: 30 stage: ${opt:stage, self:custom.defaultStage} region: ap-northeast-1 # Lambda用の権限 iamRoleStatements: - Effect: Allow Action: - dynamodb:Query - dynamodb:Scan - dynamodb:GetItem - dynamodb:PutItem - dynamodb:UpdateItem - dynamodb:DeleteItem Resource: "arn:aws:dynamodb:${aws:region}:*:table/${env:DYNAMODB_TABLE}" # Lambda functions: webhook: handler: handler.webhook events: - http: path: webhook method: post cors: true environment: OPENAI_API_KEY: ${env:OPENAI_API_KEY} LINE_CHANNEL_SECRET: ${env:LINE_CHANNEL_SECRET} LINE_CHANNEL_ACCESS_TOKEN: ${env:LINE_CHANNEL_ACCESS_TOKEN} DYNAMODB_TABLE: ${env:DYNAMODB_TABLE} # DynamoDB resources: Resources: MessageHistoryTable: Type: AWS::DynamoDB::Table Properties: TableName: ${env:DYNAMODB_TABLE} AttributeDefinitions: - AttributeName: user_id AttributeType: S - AttributeName: timestamp AttributeType: N KeySchema: - AttributeName: user_id KeyType: HASH - AttributeName: timestamp KeyType: RANGE ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1 plugins: - serverless-python-requirements
インフラの中で試行錯誤したポイントはLambdaのタイムアウト値とDynamoDBの設計です。
タイムアウト値についてはデフォルトが6秒ですが、そのままでは結構な頻度でタイムアウトが発生したため30秒にしました。
また、DynamoDBについては履歴の管理を想定したテーブル設計が必要でした。
テスト用なので自分しか使わない想定ですが、複数ユーザーに対応できるように、user_id を追加しています。
そして、user_id をパーティションキー、timestamp をソートキーとして設定することで、「時系列でソートされたユーザー単位の履歴」を取得できるようにしています。
| 属性名 | 型 | キー |
|---|---|---|
| user_id | string | パーティションキー |
| message | string | |
| timestamp | number | ソートキー |
問題としては、完全に同じtimestampでデータを保存しようとするとキーが重複してエラーになることですが、現実的にはほぼ発生しないと判断し今回は無視しています。
DynamoDBの設計自体にあまり慣れていないため、より良い方法があればご教示いただけると嬉しいです。
handlerの実装
次に、handlerの実装について説明します。
APIを呼び出す部分は以下のライブラリを使用しています。
github.com
検証中に返信が返ってこないことがあったため、処理ごとにログを出力しています。
また、DynamoDBから取得する履歴は、とりあえず10件としています。
これは、履歴が多すぎると入力トークン数の上限に引っかかるという問題があるためです。
履歴を残さないと文脈を理解できない一方、多すぎると問題が発生するということで塩梅が難しいですね。
import json import os from shutil import ExecError import time import uuid import openai import boto3 from boto3.dynamodb.conditions import Key from linebot import LineBotApi, WebhookHandler from linebot.exceptions import InvalidSignatureError, LineBotApiError from linebot.models import MessageEvent, TextMessage, TextSendMessage # 環境変数から必要な情報を取得 OPENAI_API_KEY = os.environ['OPENAI_API_KEY'] LINE_CHANNEL_SECRET = os.environ['LINE_CHANNEL_SECRET'] LINE_CHANNEL_ACCESS_TOKEN = os.environ['LINE_CHANNEL_ACCESS_TOKEN'] DYNAMODB_TABLE = os.environ['DYNAMODB_TABLE'] openai.api_key = OPENAI_API_KEY line_bot_api = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(LINE_CHANNEL_SECRET) dynamodb = boto3.resource('dynamodb') table = dynamodb.Table(DYNAMODB_TABLE) def webhook(event, context): print("Webhook called") signature = event["headers"].get("x-line-signature") or event["headers"].get("X-Line-Signature") body = event['body'] try: handler.handle(body, signature) except InvalidSignatureError: return { 'statusCode': 400, 'body': json.dumps({'message': 'Invalid signature'}) } return { 'statusCode': 200, 'body': json.dumps({'message': 'OK'}) } @handler.add(MessageEvent, message=TextMessage) def handle_message(event): send_timestamp = int(time.time() * 1000) print("Handling message") user_id = event.source.user_id user_message = event.message.text user_message_obj = {"role": "user", "content": user_message} print(f"User message: {user_message}") # 履歴の取得 message_history = get_message_history(user_id) # 履歴の順序を変えて最新のメッセージを追加 messages = [{"role": item["message"]["role"], "content": item["message"]["content"]} for item in reversed(message_history)] messages.append(user_message_obj) print(f"Message history: {messages}") # API呼び出し try: openai_response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=messages, request_timeout=20 ) except Exception as e: print(f"Error generating AI response: {e}") line_bot_api.reply_message(event.reply_token, TextSendMessage(text="エラーが発生しました。AIからの応答の生成に失敗しました。")) return # レスポンスの取得 ai_message = openai_response.choices[0].message.content ai_message_obj = {"role": "assistant", "content": ai_message} receive_timestamp = int(time.time() * 1000) print(f"AI message: {ai_message}") # LINEへの返答 try: line_bot_api.reply_message(event.reply_token, TextSendMessage(text=ai_message)) except LineBotApiError as e: print(f"Error sending AI response: {e}") return # ユーザー発言の保存 try: save_message_to_history(user_id, user_message_obj, send_timestamp) except Exception as e: print(f"Error saving user message: {e}") line_bot_api.reply_message(event.reply_token, TextSendMessage(text="エラーが発生しました。メッセージの保存に失敗しました。")) return # AI発言の保存 try: save_message_to_history(user_id, ai_message_obj , receive_timestamp) except Exception as e: print(f"Error saving AI message: {e}") line_bot_api.reply_message(event.reply_token, TextSendMessage(text="エラーが発生しました。メッセージの保存に失敗しました。")) def get_message_history(user_id, limit=10): print(f"Getting message history for user: {user_id}") response = table.query( KeyConditionExpression=Key('user_id').eq(user_id), Limit=limit, ScanIndexForward=False ) return response['Items'] def save_message_to_history(user_id, message, timestamp): print(f"Saving message to history: {message}") table.put_item( Item={ 'user_id': user_id, 'timestamp': timestamp, 'message': message } )
requirements
そして、最後にrequirements.txtです。執筆時点での最新版になっています。
line-bot-sdk==2.4.2 boto3==1.26.96 openai==0.27.2
デプロイ
ここまでできたらServerlessFrameworkでデプロイします。
sls deploy --aws-profile {profile} --stage dev
作成に成功するとエンドポイントが表示されるので、Messaging APIのWebhook URLに設定します。
説明は過去の自分の記事や他の記事を確認してください。
これで構築と設定は完了です。

LINE Botを追加し、メッセージを送信するとデモのようにやりとりすることができます。
おわりに
以上、簡単にではありますがServerless Frameworkを使ってバックエンドを構築し、LineBotを作ってみました。
ひとまず動くところまでは確認できたのでよかったです。
ただ、はじめにでも書いたようにタイムアウトの問題や、履歴のリセット機能や人格の設定など改善したい点はまだまだありますね。
このような改善ポイントについては引き続き検証、対応していきたいと思います!
以上、拙い記事ですが何かの参考になれば幸いです。
参考にさせていただいた記事
おわりに
雰囲気でDocker Composeを触っている状態から脱するために調べたこと(2023)
 エンジニアの岡村です。
エンジニアの岡村です。
自分はサーバーがメインではなく、あまり業務でガッツリ触るわけでもないのですが、最近それなりに活用するようになってきました。しかし、ネット上の日本語情報を読んでいるだけではこれの書き方が正しいのかよく分からない、と悩むことが結構あったため、色々情報を漁ってみました。 この記事は、特に自分が気になった部分の調べた結果を記事に纏めてみたものです。対象読者はdocker-composeを雰囲気でupやdownは叩けるけどComposeファイルの書き方がよく分からんとなってる人です。
- Docker Composeの概要とcompose.yaml、Compose Specの関係
- compose.yamlの書き方は Compose Specに準拠すればOK
- Compose Specの場所
- 推奨のファイル名はcompose.yaml
- compose.yaml内にバージョンを記述するのは非推奨
- 環境変数の定義方法は2種類あるがどちらでもOK
- docker-composeコマンドとdocker composeコマンドは後者の方が新しい
- (おまけ)Windows環境における改行コードの問題とその対策
- 終わり
Docker Composeの概要とcompose.yaml、Compose Specの関係
docker-composeは複数のコンテナが連携して動作する、コンテナベースのアプリケーションを構築する仕組みです。動作させるにはcompose.yamlという構成ファイルを記述し、Docker composeに読み込ませます。
最新のcompose.yamlを書くにあたっては、Compose Specという概念が関わってきます。Compose Specは、プラットフォームに依存しない、マルチコンテナベースのアプリケーションを定義する為の標準仕様です。所謂HTML Living Standardのようなもので、Compose Specでcompose.yamlをどのように書くべきか、書かれたものがどの様に動作するべきかが定義されています。
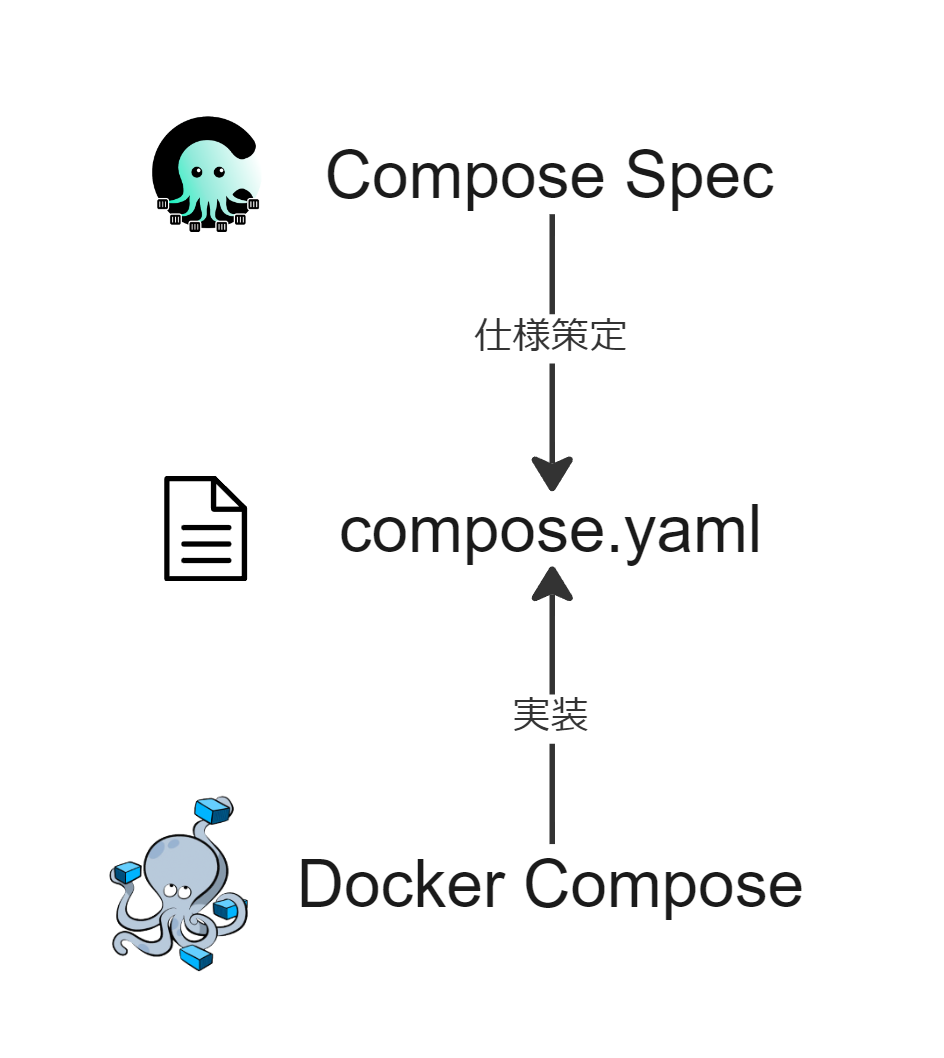
ここでのプラットフォームとは、Docker ComposeやAWS、Azureなどを指します。Compose Specでは、定められた仕様を各プラットフォームが実装することを想定しており、compose.yamlを読み込み動作させるアプリをDocker Composeに限定していない様です。
Dockerのドキュメントの日本語訳等でCompose 仕様という言葉が出たらこのCompose Specの事を指しています。
compose.yamlの書き方は Compose Specに準拠すればOK
Docker Engine 19.03.0+ 及び Compose 1.27.0+ であれば、Compose Spec形式のcompose.yamlがサポートされています。ただし、Compose Specに関しては明確にバージョンが切られているわけではないので、Docker Composeのバージョンが古ければ一部の属性がサポートされていない可能性があります。
ちなみに、古いバージョンとCompose Specとの関係は以下のようになっています。
Compose V1 -- 最初期の、docker composeがdocker-composeとして、dockerとは独立したアプリとして開発されており、Compose Specもない頃のものです。非推奨のラベルがついている他、2023年6月末に全てのバージョンのDocker Desktopから削除され、使用できなくなるとアナウンスされているため、使用するべきではありません。手元のファイルがCompose V1の仕様で書かれているのであれば、引き続き使用するには変換作業が必要です。
Compose V2 及び Compose V3 -- Compose Specへの準拠を行った新しいバージョンのComposeファイルです。元々V2、V3...とバージョンを進めていく予定だったのが、Compose Specに統合された様です。
Compose Specの場所
GitHubにあります。RFC2119に準拠した文章になっている為、読みやすく明確になっており、最新の仕様を追うだけであれば、こちらを読んでおけば問題なさそうです。
これ以降は自分がCompose Specとその歴史的背景にたどり着くまでの間、特に気になってた部分に関して、ちょっとした解説を交えて紹介していきます。
推奨のファイル名はcompose.yaml
(GitHub上で)圧倒的に使われているのはdocker-compose.ymlですが、Compose Specではcompose.yamlが推奨されています。
手元で試してみたところ(compose v2.15.1)、composeファイル名が指定されていない時は以下の順番でファイルが選ばれました。
- compose.yaml(最優先)
- compose.yml
- docker-compose.yml
- docker-compose.yaml
元々はdocker-compose.ymlがデフォルトだったのですが、2020年初頭に変更されたようです。
dockerという名前がベンダー固有のものであり、一方で前述の通りCompose SpecはDockerに依存しないものであるからという理由で変えたみたいですね。
compose.yaml内にバージョンを記述するのは非推奨
最新の仕様では、ファイル内にバージョンを記述することは非推奨となっています。
spec.md#version-top-level-element
Compose Specによると、下位互換性の為に残されていますが、実装においてバージョン情報を参照して動作を変更する様なことはすべきではなく、そのアプリがリリースされた時点での最新のCompose Specに従うべきと書かれているため、version要素によって挙動が変化することはなさそうです。
Compose V1もバージョンを指定しないので、Compose V1とCompose Specのファイルが混同されそうな気がしますが、Compose V1はサポートを終了するので問題ないという判断をしたのでしょうか?
環境変数の定義方法は2種類あるがどちらでもOK
以下の様に、環境変数の定義はリストだけではなく辞書形式でも書けるようになっています。
# リスト形式 environment: - KEY=VALUE - KEY2=VALUE2 - KEY3=123
# 辞書形式 environment: KEY: VALUE KEY2: 'true' KEY3: '123'
個人的にはGitHub Actionsと同じように書けて、yamlのハイライトも効くので読みやすい後者の方が好きです。ただし文字列しか受け付けないので、true等のyamlで意味を持つ文字はクウォートで囲んでやる必要があります。
docker-composeコマンドとdocker composeコマンドは後者の方が新しい
docker-composeコマンドはV1の時代からありましたが、docker composeコマンドはV2(Compose Spec)時代に新しく作られました。
differences-between-compose-v1-and-compose-v2
docker composeコマンドの方がCompose Specに準拠しており、クラウドプラットフォームへのデプロイなどが行えるようです。
最新版ではどちらのコマンドも利用可能です。Compose V1のサポートが終了しても、docker-composeコマンドはエイリアスとして残し続ける方針のようです。
(おまけ)Windows環境における改行コードの問題とその対策
最後に脱線ですが、Dockerをwindowsで動かすときは改行コードをlfに統一しましょう。 そうしないと、linuxコンテナを動かすときに改行コードで消耗することになります。
auto-crlfを無効化しましょう。
git config --local core.autocrlf input
ついでにcompose.yamlと同じ階層に.editorconfigファイルも設置しておきましょう。
root = true [*] end_of_line = lf insert_final_newline = true
終わり
Compose Specとその歴史的背景を把握したことで、だいぶ認識がスッキリした様に思います。これで安心して絶望の谷に落ちていくことができそうです。
OpenAIが公開したChatGPTとWhisperのAPIをUnityでサクッと触れるようにした

こんにちは、エンジニアリングマネージャーの渡辺(@mochi_neko_7)です。
つい先日の2023/03/01、OpenAIがChatGPTとWhisperの新しいAPIを公開して話題になりましたね。
利用料金も1/10程度になり、気軽に利用しやすくなりました。
これらはWeb APIとして公開されているものなので、Unity/C#からも適切にHTTP通信をすれば利用することができます。
そこで実際に、UnityからChatGPT APIとWhisper APIを利用するためのライブラリを趣味で開発しました。
API自体の解説をしている方は既にいらっしゃいますのであまり詳しくは触れませんが、自分がドキュメントを全て英語で書いているのもあり、記事で簡単に紹介ができればと思います。
OpenAI API Keyの発行に関して
本記事で紹介するChatGPT API、Whisper APIはどちらも利用料が発生するもので、事前にアカウント登録や支払情報の登録、API Keyの発行が必要になります。
詳しい手順等は調べれば出てくると思いますのでここでは省略します。
本記事で紹介する内容を自分で触ってみたい方は、事前にAPI Keyを発行してください。
念の為注意事項として、API Keyは他人や外部に漏れると勝手に使用されてしまい課金が発生する恐れがあるため、GitHub等に載らないよう .gitignore で指定したり、環境変数を利用したり、自前のサーバーを介すなど適切に取り扱ってください。
ChatGPT API
ChatGPT APIは、ChatGPTの gpt-3.5-turbo(最新版) or gpt-3.5-turbo-0301(2023/03/01時点で固定されたモデル) のモデルを使用してChat Completion(会話の補完、対話)ができるAPIです。
概要はこちらにまとられています。
これをUnityで利用できるようにしているのがこちらのRepositoryです。
これを利用したい方は、このソースコードを配置する必要はなく、UPM(Unity Package Manager)によるパッケージのインポート機能だけで利用することが可能です。
セットアップ手順
利用したいUnityのプロジェクトの /Packages/manifest.json を開いて、"dependencies": の配列に次の2行を追加してください。
{ "dependencies": { "com.mochineko.chatgpt-api": "https://github.com/mochi-neko/ChatGPT-API-unity.git?path=/Assets/Mochineko/ChatGPT_API#0.1.1", "com.unity.nuget.newtonsoft-json": "3.0.2", ... } }
#0.1.1 の部分はTagのバージョンなので適宜最新版を利用するなどしてください。
もし既にNewtonsoft.Jsonを利用されている場合は、2行目の依存関係は不要です。
これだけでライブラリの準備は完了です。
仕様
公式のガイド記事はこちらです。
WebAPIの使用はこちらに記載されています。
大まかな仕様としては、3つのRole
- system:状況設定(いわゆるPrompt)
- user:ユーザーの会話の入力
- assistant:ChatGPTの会話の出力
のメッセージのリストを渡して、その後に続く適切なassistantメッセージを返す(Chat Completion)といったものです。
ただしメッセージの長さ(厳密にはToken数)は生成後のメッセージと合わせて4096までという制約があることに注意が必要です。
実装側としては過去のメッセージのやり取りを保存しておき、新しいRequestを投げる際に一緒にパラメータに含める形になります。
メッセージのリストは記憶や文脈に相当する情報で、現在は最も簡易な形でしか実装していませんが、LangChainのMemoryのように渡し方を工夫してあげるともっと面白いことになると思います。
Unityでの使用方法
サンプルのComponent実装を用意しているので、最低限の設定項目や使用方法はこちらを参考にしてみてください。
Requestのパラメータを詳細に設定できるインターフェースも用意してあるため、使いたいシチュエーションに合わせて設定をしてください。
ちなみにメッセージのリストを自分で管理したい場合は都度Connectionのインスタンスを作って使用してもらって大丈夫です。
HttpClientのインスタンスは内部でSingletonにしてあるのでそこまでオーバーヘッドはないはずです。
Whisper API
Whisper APIは、Whisperの whisper-1 というモデルを使用してTranscription(音声をテキストに変換、文字起こし)とTranslation(音声の内容を英語に翻訳してテキストに変換)ができるAPIです。
概要はこちらにまとられています。
これをUnityで利用できるようにしているのがこちらのRepositoryです。
これを利用したい方はChatGPT APIと同様、このソースコードを配置する必要はなく、UPM(Unity Package Manager)によるパッケージのインポート機能だけで利用することが可能です。
セットアップ手順
利用したいUnityのプロジェクトの /Packages/manifest.json を開いて、"dependencies": の配列に次の2行を追加してください。
{ "dependencies": { "com.mochineko.whisper-api": "https://github.com/mochi-neko/Whisper-API-unity.git?path=/Assets/Mochineko/Whisper_API#0.1.0", "com.unity.nuget.newtonsoft-json": "3.0.2", ... } }
#0.1.0 の部分はTagのバージョンなので適宜最新版を利用するなどしてください。
もし既にNewtonsoft.Jsonを利用されている場合は、2行目の依存関係は不要です。
これだけでライブラリの準備は完了です。
仕様
公式のガイド記事はこちらです。
WebAPIの使用はこちらに記載されています。
Whisperの仕様はシンプルで、音声データをRequestのパラメータと一緒に渡すとテキストが返ってくるというものです。
Responseのテキストの形式はデフォルトではJSONですが、パラメータで変更が可能なため、適宜stringを変換して利用します。
言語やPromptを指定すると精度が上がるようです。
Unityでの使用方法
サンプルのComponent実装を用意しているので、最低限の設定項目や使用方法はこちらを参考にしてみてください。
Requestのパラメータを詳細に設定できるインターフェースも用意してあるため、使いたいシチュエーションに合わせて設定をしてください。
都度Requestのパラメータを調整したい場合はその都度インスタンスを生成して使用してください。
実装する上で注意したこと
実装自体はソースコードを見ていただければ分かる通りそれほど難しくありません。
HTTP通信でのWebAPIの叩き方やJSONの取り扱いがあればご自身でも実装できると思います。
ちょっとハードルが高いとという方はUPMで利用してみてください。
API Referenceには記述が見当たらなかったのですが、エラーのResponseはこのようなJSONで共通のようです。
どうでも良い個人的なこだわりとしては、意図的にUnity標準のUnityWebRequestとJsonUtilityを使用せず、それぞれHttpClientとNewtonsoft.Jsonで代替しています。
自分が使い慣れているというのもありますが、これらを除外できるとUnityのコードに全く依存しなくなるため(実際にAssemblyDefinitionを見ていただくと No Endine Reference = true になっているのがわかると思います)、Unityのバージョンの影響をほとんど受けなかったり(ただ nullable を使ってしまっているのでC#のバージョンの制約がありますが)、やらないと思いますがPure C#に切り出せるというメリットもあります。
あとはModelの指定をenumでできるようにしているのも扱いやすさの観点での個人的嗜好です。
今後の使い道など
ChatGPTとWhisperを組み合わせると、
音声入力 -> 文字起こし -> ChatGPTと会話
をすることができます。
既に実装されている方がいるように、更に音声合成を組み合わせると
音声入力 -> 文字起こし -> ChatGPTと会話 -> テキストから音声合成
と音声での会話の一連の流れが成立します。
なので次はVOICEVOXによる音声合成ができるようAPI部分のライブラリを作成してみたり、ChatGPT APIの会話の記憶部分をより高度にするためにLangChainのJavaScript版をNode.jsでAPIサーバーとして立ててみたりしようかなと考えています。
おわりに
ChatGPTもWhisperも使い道はさまざまで可能性は無限大なAIですが、Unityで利用できると3DCGやXRとの組み合わせが簡単にできるようになります。
自分のUnity製アプリに組み込んでみたいという方はUPMでサクッと導入できますのでぜひ触ってみてください。
Pull Request、fork、ライセンスの範囲内での改変等も歓迎ですので、もしフィードバックなどありましたらGitHubやTwitterでご連絡いただけますと幸いです。