こんにちは、フロントエンドエンジニアの堀江(@nandemo_3_)です。
フロントエンドチームの業務改善の観点から、以前からissueに上がっていた本件を調査、対応しましたので備忘録として紹介いたします。
背景
フロントエンドチームが開発、運用しているSYNMNアプリの管理画面では、HTMLヘッダーのメタ情報に、package.jsonのversionを指定しております。
現状、こちらのバージョン管理は手動で行なっており、以前から手間という認識をしておりました。
緊急性は高くありませんが、業務改善となるので取り組んでみました。
現状
以下のように、package.jsonのversionをHTMLヘッダーのメタ情報にバージョンを指定しています。
// package.json { "name": "app", "version": "0.1.2", "scripts": { "build": "cross-env NEXT_PUBLIC_APP_PACKAGE_VERSION=$npm_package_version next build", // 省略.... }
// _app.tsx <Head> <title key="title">{siteTile}</title> <meta name="viewport" content="initial-scale=1, width=device-width" /> <link rel="icon" type="image/png" href="/favicon.png" /> <meta name="synmn:version" content={`${process.env.NEXT_PUBLIC_APP_PACKAGE_VERSION}`} /> </Head>
また、管理画面は企業様向けのPlanet機能と、アドミン権限向けのProvider機能で分かれており、
ソースコードおよびpackage.json(今回更新する対象)もフォルダで分割されております。
. └── apps ├── planet-app │ └── package.json └── provider-app └── package.json
ゴール
- GitHub Actionsを用いて、実現する
- 作業ブランチからmainにPRした際に、package.jsonのversionを自動でインクリメントし、commitする(その後、手動でマージ)
- planet-appおよびprovider-app配下のpackage.jsonどちらも更新する
参考にさせていただいたテック記事
こちらのテック記事を参考させていただきました。
使い方はPRのラベルに、release:major release:minor release:patchを付与することで、それぞれのバージョンが更新されます。
ルート直下のpackage.jsonのversionを更新する
テック記事のコードが動作するか検証します。(大事)
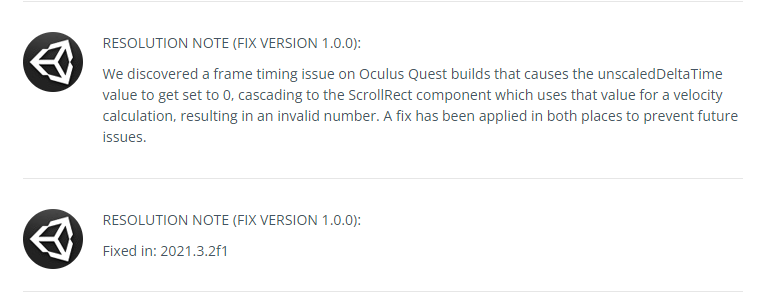
エラー発生
GitHub Actionsのワークフローでエラーが発生。 そう簡単にはいきません。
エラー①
ワークフローのログにはpnpm: command not foundと表示されております。

package.jsonのversionをpnpm versionを用いて更新しているので、
uses: pnpm/action-setup@v2を追加してpnpmを使えるようにします。
# 省略... update_version: # 省略... steps: # 省略... - uses: pnpm/action-setup@v2 with: version: 7.1.0 # 省略...
エラー②
package.jsonのversionが変わりません。
pnpm version --majorの動作確認をローカルで実施しましたが、やはり変わっていません。
% pnpm version --major --no-git-tag-version
v3.0.0
% pnpm version --major --no-git-tag-version
{
'gh-action-release-ver-increment': '3.0.0',
npm: '9.4.2',
node: '16.14.2',
v8: '9.4.146.24-node.20',
uv: '1.43.0',
zlib: '1.2.11',
brotli: '1.0.9',
ares: '1.18.1',
modules: '93',
nghttp2: '1.45.1',
napi: '8',
llhttp: '6.0.4',
openssl: '1.1.1n+quic',
cldr: '40.0',
icu: '70.1',
tz: '2021a3',
unicode: '14.0',
ngtcp2: '0.1.0-DEV',
nghttp3: '0.1.0-DEV'
}
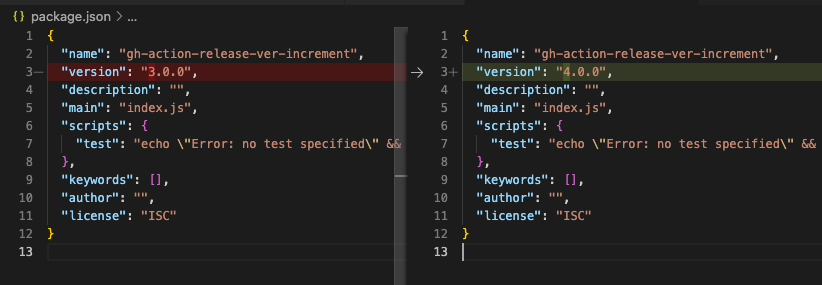
pnpm version --majorだとバージョンが変わらないので、pnpm version majorに変更しました。(minorとpatchも同様です)
ローカルでの動作確認でversionが変わっていることを確認。
% pnpm version major --no-git-tag-version
v4.0.0
% pnpm version --major --no-git-tag-version
{
'gh-action-release-ver-increment': '4.0.0',
npm: '9.4.2',
node: '16.14.2',
v8: '9.4.146.24-node.20',
uv: '1.43.0',
zlib: '1.2.11',
brotli: '1.0.9',
ares: '1.18.1',
modules: '93',
nghttp2: '1.45.1',
napi: '8',
llhttp: '6.0.4',
openssl: '1.1.1n+quic',
cldr: '40.0',
icu: '70.1',
tz: '2021a3',
unicode: '14.0',
ngtcp2: '0.1.0-DEV',
nghttp3: '0.1.0-DEV'
}
こちら、ソース上での差分となります。
エラー③
ワークフローのGitコマンドを実行した際に、403エラーが発生しました。

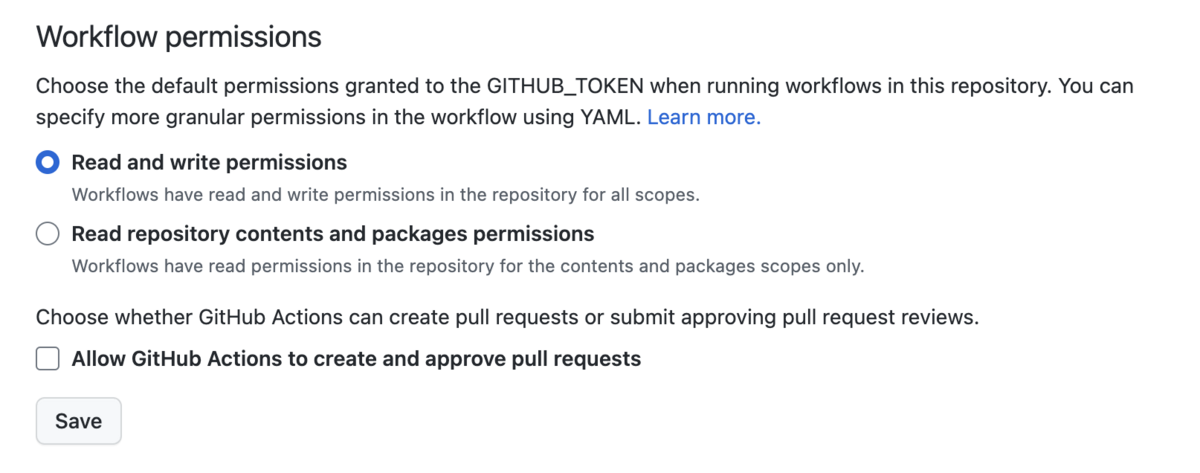
GitHub ActionsのWorkflowにリポジトリに対する書き込み権限がないため、エラーとなっているので、権限を付与しました。
リポジトリのSettings -> Actions -> General -> Workflow permissions の順に遷移し、
Read and write permissionsに変更しました。
無事成功

これで、ルート直下のpackage.jsonがバージョンアップできました。
ソースコード
ここまでのソースコード全文はこちらです。
GitHub - nandemo3/gh-action-release-version-increment at package_in_root
name: Update release version in package.json on: pull_request: branches: - main types: - labeled - unlabeled jobs: check_release_label: runs-on: ubuntu-latest steps: - name: Check release label if: | !contains(github.event.pull_request.labels.*.name, 'release:patch') && !contains(github.event.pull_request.labels.*.name, 'release:minor') && !contains(github.event.pull_request.labels.*.name, 'release:major') run: | echo "::error::リリースラベルを付与してください。labels: release:patch, release:minor, release:major" exit 1 version_diff: if: | contains(github.event.pull_request.labels.*.name, 'release:patch') || contains(github.event.pull_request.labels.*.name, 'release:minor') || contains(github.event.pull_request.labels.*.name, 'release:major') runs-on: ubuntu-latest outputs: chagned: ${{ steps.get_diff.outputs.changed }} steps: - uses: actions/checkout@v3 - name: Get branch to marge run: git fetch origin ${{ github.base_ref }} --depth=1 - name: Keep version changes id: get_diff run: echo "changed=$(git diff origin/${{ github.base_ref }} HEAD --relative "./package.json" | grep "^+.\+version" | wc -l)" >> $GITHUB_OUTPUT update_version: runs-on: ubuntu-latest needs: [version_diff] if: needs.version_diff.outputs.chagned == '0' steps: - uses: actions/checkout@v3 with: ref: ${{ github.event.pull_request.head.ref }} - uses: actions/setup-node@v3 with: node-version: 16 - uses: pnpm/action-setup@v2 with: version: 7.1.0 - name: Set git information if: steps.diff.outputs.changed == '0' run: | git config --global user.name 'github-actions[bot]' git config --global user.email 'github-actions[bot]@users.noreply.github.com' git remote set-url origin https://github-actions:${GITHUB_TOKEN}@github.com/${GITHUB_REPOSITORY} env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} - name: Update version(patch) if: contains(github.event.pull_request.labels.*.name, 'release:patch') run: pnpm version patch --no-git-tag-version - name: Update version(minor) if: contains(github.event.pull_request.labels.*.name, 'release:minor') run: pnpm version minor --no-git-tag-version - name: Update version(major) if: contains(github.event.pull_request.labels.*.name, 'release:major') run: pnpm version major --no-git-tag-version - name: Commit and push to PR run: | git add . git commit -m "v$(grep version package.json | awk -F \" '{print $4}')" git push origin HEAD
実環境に合わせて実装
フォルダ構成に合わせ、PlanetとProviderのそれぞれのpackage.jsonを更新します。
デモのため、便宜上各フォルダをApp1とApp2にしています。
元々のyamlでは、ルートのpackage.jsonをターゲットにしているので、各フォルダ配下をターゲットにするよう変更します。
具体的には、実行コマンドの前にworking-directoryを入れて、ディレクトリを指定します。
# 省略... jobs: version_diff_app1: if: | contains(github.event.pull_request.labels.*.name, 'release:patch') || contains(github.event.pull_request.labels.*.name, 'release:minor') || contains(github.event.pull_request.labels.*.name, 'release:major') runs-on: ubuntu-latest outputs: chagned: ${{ steps.get_diff.outputs.changed }} steps: - uses: actions/checkout@v3 - name: Get branch to marge run: git fetch origin ${{ github.base_ref }} --depth=1 - name: Keep version changes id: get_diff working-directory: ./App1 run: echo "changed=$(git diff origin/${{ github.base_ref }} HEAD --relative package.json | grep "^+.\+version" | wc -l)" >> $GITHUB_OUTPUT version_diff_app2: if: | contains(github.event.pull_request.labels.*.name, 'release:patch') || contains(github.event.pull_request.labels.*.name, 'release:minor') || contains(github.event.pull_request.labels.*.name, 'release:major') runs-on: ubuntu-latest outputs: chagned: ${{ steps.get_diff.outputs.changed }} steps: - uses: actions/checkout@v3 - name: Get branch to marge run: git fetch origin ${{ github.base_ref }} --depth=1 - name: Keep version changes id: get_diff working-directory: ./App2 run: echo "changed=$(git diff origin/${{ github.base_ref }} HEAD --relative package.json | grep "^+.\+version" | wc -l)" >> $GITHUB_OUTPUT update_version: runs-on: ubuntu-latest needs: [version_diff_app1, version_diff_app2] if: | needs.version_diff_app1.outputs.chagned == '0' || needs.version_diff_app2.outputs.chagned == '0' steps: # 省略... - name: Update version App1(patch) if: contains(github.event.pull_request.labels.*.name, 'release:patch') working-directory: ./App1 run: pnpm version patch --no-git-tag-version # 省略... - name: Update version App2(patch) if: contains(github.event.pull_request.labels.*.name, 'release:patch') working-directory: ./App2 run: pnpm version patch --no-git-tag-version # 省略...
ワークフロー実行中に競合が発生


各package.jsonごとに、変更をコミットしており、
片方のコミット後に、もう片方が変更しようとして競合が起きているようです。
# 省略... update_version_app1: # 省略... - name: Commit and push to PR working-directory: ./App1 run: | git add . git commit -m "v$(grep version package.json | awk -F \" '{print $4}')" git push origin HEAD update_version_app2: # 省略... - name: Commit and push to PR working-directory: ./App2 run: | git add . git commit -m "v$(grep version package.json | awk -F \" '{print $4}')" git push origin HEAD # 省略...
特に、コミットを分ける理由がないので、1回にまとめるようにします。
# 省略... - name: Commit and push to PR working-directory: ./ run: | git add . git commit -m "App1 v$(grep version './App1/package.json' | awk -F \" '{print $4}'), App2 v$(grep version './App2/package.json' | awk -F \" '{print $4}')" git push origin HEAD # 省略...
無事、2つとも更新することができました。

おまけ
参考にさせていただいたテック記事ですと、PRにラベルがないとワークフローがエラーとなりますが、
私としては、バージョンを上げたといときだけバージョンをあげ、それ以外は失敗せずマージさせたいので
ラベルのチェック処理は削除しました。
ソースコード
今回対応したソースコード全文はこちらです。
name: Update release version in package.json on: pull_request: branches: - main types: - labeled jobs: version_diff_app1: if: | contains(github.event.pull_request.labels.*.name, 'release:patch') || contains(github.event.pull_request.labels.*.name, 'release:minor') || contains(github.event.pull_request.labels.*.name, 'release:major') runs-on: ubuntu-latest outputs: chagned: ${{ steps.get_diff.outputs.changed }} steps: - uses: actions/checkout@v3 - name: Get branch to marge run: git fetch origin ${{ github.base_ref }} --depth=1 - name: Keep version changes id: get_diff working-directory: ./App1 run: echo "changed=$(git diff origin/${{ github.base_ref }} HEAD --relative package.json | grep "^+.\+version" | wc -l)" >> $GITHUB_OUTPUT version_diff_app2: if: | contains(github.event.pull_request.labels.*.name, 'release:patch') || contains(github.event.pull_request.labels.*.name, 'release:minor') || contains(github.event.pull_request.labels.*.name, 'release:major') runs-on: ubuntu-latest outputs: chagned: ${{ steps.get_diff.outputs.changed }} steps: - uses: actions/checkout@v3 - name: Get branch to marge run: git fetch origin ${{ github.base_ref }} --depth=1 - name: Keep version changes id: get_diff working-directory: ./App2 run: echo "changed=$(git diff origin/${{ github.base_ref }} HEAD --relative package.json | grep "^+.\+version" | wc -l)" >> $GITHUB_OUTPUT update_version: runs-on: ubuntu-latest needs: [version_diff_app1, version_diff_app2] if: | needs.version_diff_app1.outputs.chagned == '0' || needs.version_diff_app2.outputs.chagned == '0' steps: - uses: actions/checkout@v3 with: ref: ${{ github.event.pull_request.head.ref }} - uses: actions/setup-node@v3 with: node-version: 16 - uses: pnpm/action-setup@v2 with: version: 7.1.0 - name: Set git information if: steps.diff.outputs.changed == '0' run: | git config --global user.name 'github-actions[bot]' git config --global user.email 'github-actions[bot]@users.noreply.github.com' git remote set-url origin https://github-actions:${GITHUB_TOKEN}@github.com/${GITHUB_REPOSITORY} env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} - name: Update version App1(patch) if: contains(github.event.pull_request.labels.*.name, 'release:patch') working-directory: ./App1 run: pnpm version patch --no-git-tag-version - name: Update version App1(minor) if: contains(github.event.pull_request.labels.*.name, 'release:minor') working-directory: ./App1 run: pnpm version minor --no-git-tag-version - name: Update version App1(major) if: contains(github.event.pull_request.labels.*.name, 'release:major') working-directory: ./App1 run: pnpm version major --no-git-tag-version - name: Update version App2(patch) if: contains(github.event.pull_request.labels.*.name, 'release:patch') working-directory: ./App2 run: pnpm version patch --no-git-tag-version - name: Update version App2(minor) if: contains(github.event.pull_request.labels.*.name, 'release:minor') working-directory: ./App2 run: pnpm version minor --no-git-tag-version - name: Update version App2(major) if: contains(github.event.pull_request.labels.*.name, 'release:major') working-directory: ./App2 run: pnpm version major --no-git-tag-version - name: Commit and push to PR working-directory: ./ run: | git add . git commit -m "App1 v$(grep version './App1/package.json' | awk -F \" '{print $4}'), App2 v$(grep version './App2/package.json' | awk -F \" '{print $4}')" git push origin HEAD
最後に
package.jsonのversion更新をGitHub Actionsを用いて行なってみました。
弊社プロダクトのフォルダ構成が少し特殊だったので、ちょっと苦戦しましたが、無事できました。
どこかの誰かに参考になれば幸いです。
参考文献
GitHub Actions を使ってラベルで package.json の version を更新する
GitHub - pnpm/action-setup: Install pnpm package manager
python - Permission denied to github-actions[bot] - Stack Overflow