LangChainをFastAPI経由でUnityで利用する

こんにちは、エンジニアリングマネージャーの渡辺(@mochi_neko_7)です。
先日、LangChainというLLMを扱うPythonライブラリをDocker上で動かしてみた話を記事で紹介しました。
今回はその発展として、ローカルDocker上のLangChainをFastAPIを使ってAPIサーバー化して、APIを通してUnityからLangChainの機能を利用できることを紹介します。
特別高度なことはしておらず既存の技術やフレームワークの組み合わせになりますが、同じようなことを自分で実装してみたいという方の参考になれば幸いです。
構成
今回作成するシステムの全体構成は下記のようになります。
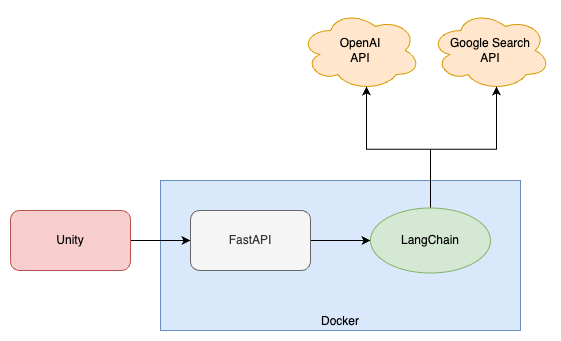
Unityから触るのはFastAPIのサーバーですが、その内部でLangChainを使用し、さらにLangChainがOpenAIやGoogle検索のAPIなどを使用する、といった形です。
FastAPIを採用しているのはLangChainと同じPythonで書けるWebフレームワークで、かつ手軽にセットアップができるからです。
今回はFastAPIのAPIサーバーはDockerを使ってLocalマシン上に立てます。
環境
- macOS 13.3.1 (ARM64)
- Docker Engine v20.10.24
- LangChain 0.0.142
- FastAPI 0.95.1
- Unity 2021.3.0f1
前提
前回記事には事前に目を通していることを前提として、今回はFastAPIとUnityを使用します。
- APIサーバーの基本的な知識
- Pythonが分かる
- FastAPIは初見
- OpenAPIは読める
- Unityは十分触れる
ただ自分はUnityクライアントメインのエンジニアであるため、サーバーサイドは詳しくありません。趣味でNode.jsのAPIサーバー構築を少しだけ触ったことがある程度です。
ただAPIサーバーに関しては業務や趣味で触っているため、OpenAPIの読み方、Request/Responseの作法、ステータスコード、ルーティングなど基本的なことは理解しているつもりです。
最低限動かすだけならPythonやFastAPIは調べながらでも問題ないです。
今回紹介する内容はこちらのRepositoryでも確認ができます。
例によって環境変数ファイル .env でOpenAIのAPI Keyなどのプライベートなトークンを保持して利用しているため、手元で動かしてみたい場合には注意してください。
本記事では主にLangChainを使ってFastAPIのAPIサーバーを作る流れを紹介しますので、DockerやLangChain、Unityの基本的な触り方に関してはあまり解説しないことをご承知おきください。
FastAPIのセットアップ
FastAPIはPython向けのWebフレームワークです。
一応LangChainはJavaScript版もあるためNode.jsでAPIサーバーを立てることも可能ですが、オリジナルのPython版の開発が早すぎるせいかJS版は機能が追いついていない部分もあるようですので注意してください。
まずチュートリアルに従ってFastAPIとUvicornのパッケージを追加します。
ここでは前回記事のプロジェクトをそのまま使用するため、Poetryで追加をします。
$ poetry add uvicorn $ poetry add fastapi
次に最もシンプルなサーバーコードをチュートリアルに従って書きます。
# パッケージのインポート from fastapi import FastAPI # FastAPIのインスタンス作成 app = FastAPI() # RootのAPIの定義 @app.get("/") async def root(): return {"message": "Hello World"}
このPythonファイルを langchain/src/main.py に配置し、Dockerfileの末尾を編集して起動時にサーバーとして立ち上げるようにします。
FROM --platform=arm64 python:3.9 RUN apt-get -y update WORKDIR /app RUN pip install poetry COPY pyproject.toml poetry.lock ./ RUN poetry install --no-root COPY . . EXPOSE 8000 ENTRYPOINT ["poetry", "run"] CMD ["uvicorn", "src.main:app", "--reload", "--host", "0.0.0.0", "--port", "8000"]
第二引数で先ほど作成したファイルを指定しています。
ファイルの更新でサーバーも自動更新されるよう、--reload のオプションを付けておきます。
Dockerでこれを起動して、http://127.0.0.1:8000 をブラウザで開き、{"message": "Hello World"} のJSONが返ってくるのが確認できたらサーバーが問題なく動作しています。
数行のコードでAPIサーバーのセットアップができるのはさすがですね。
また、FastAPIはOpenAPIのドキュメントを自動生成してくれますので、http://127.0.0.1:8000/docs で確認してみてください。
APIの作成
LangChainを使用したAPIを作成してみましょう。
何か適当なAgentを用意して、APIで呼び出すことを考えます。
ここではシンプルに会話のできるConversasion AgentにGoogle検索の機能を持たせたものを、ChatGPTのAPIを利用して作ってみましょう。
基本的なAgentのセットアップ方法はこちらになります。
Memoryの部分には内部で自動的に要約して履歴を圧縮できるConversationSummaryMemoryを使用してみましょう。
Google検索のToolは事前にAPI Keyの発行などの準備が必要なので、下記を参考に準備をします。
最終的には .env ファイルに3つの環境変数をセットします。
OPENAI_API_KEY=sk-XXXXXX GOOGLE_CSE_ID=XXXXXX GOOGLE_API_KEY=XXXXXXX
Agentのセットアップ方法はいくつかあるのですが、Promptを丁寧に指示してちゃんとToolを使ってくれるよう下記のようにセットアップします。
import langchain.llms from langchain import GoogleSearchAPIWrapper, LLMChain from langchain.agents import initialize_agent, AgentType, Tool, ZeroShotAgent, AgentExecutor from langchain.schema import BaseMemory def setup_agent(llm: langchain.llms.BaseLLM, memory: BaseMemory): search = GoogleSearchAPIWrapper() tools = [ Tool( name="Google Search", func=search.run, description="Useful for when you need to answer questions about current events, the current state of the world or what you don't know." ), ] prefix = """Answer the following questions as best you can. You have access to the following tools:""" suffix = """Begin! Use lots of tools, and please answer finally in Japanese. Question: {input} {agent_scratchpad}""" prompt = ZeroShotAgent.create_prompt( tools, prefix=prefix, suffix=suffix, input_variables=["input", "agent_scratchpad"] ) llm_chain = LLMChain( llm=llm, prompt=prompt) agent = ZeroShotAgent( llm_chain=llm_chain, tools=tools, memory=memory) agent_executor = AgentExecutor.from_agent_and_tools( agent=agent, tools=tools, verbose=True) return agent_executor
langchain-docker/conversational_agent.py at main · mochi-neko/langchain-docker · GitHub
APIのPath、Request、Responseを決め、FastAPIのチュートリアルを見ながら下記のように実装をします。
今回は下記のようなシンプルな例を考えます。
- Path:
agents/conversation - Method: POST
- Request: JSONに文字列のメッセージを埋め込む
- Response: JSONで文字列の結果を返す
実装例は下記になります。
from fastapi import FastAPI from langchain.llms import OpenAIChat from langchain.memory import ConversationSummaryMemory from pydantic import BaseModel from .agents import conversational_agent # FastAPIのインスタンスの作成 app = FastAPI() # LangChainで使用するインスタンスの作成 llm = OpenAIChat() memory = ConversationSummaryMemory( llm=llm, memory_key="chat_history") # Response bodyの定義 class AgentResponse(BaseModel): result: str # Root APIの定義 @app.get("/") def read_root(): return {"Hello": "World"} # Agentの作成 conversation_agent_executor = conversational_agent.setup_agent( llm=llm, memory=memory) # Request bodyの定義 class ConversationAgentRequest(BaseModel): content: str # APIの定義 @app.post("/agents/conversation", response_model=AgentResponse) async def conversation_agent(request: ConversationAgentRequest): result = conversation_agent_executor.run( input=request.content, chat_history=memory.chat_memory) return {"result": result}
langchain-docker/main.py at main · mochi-neko/langchain-docker · GitHub
JSONの型の定義にはpydanticの BaseModel を使用します。
実装が終わったらDockerを立ち上げて(既に立ち上げている場合は保存をして)、自動生成されるOpenAPIのドキュメントを http://127.0.0.1:8000/docs で確認してみましょう。
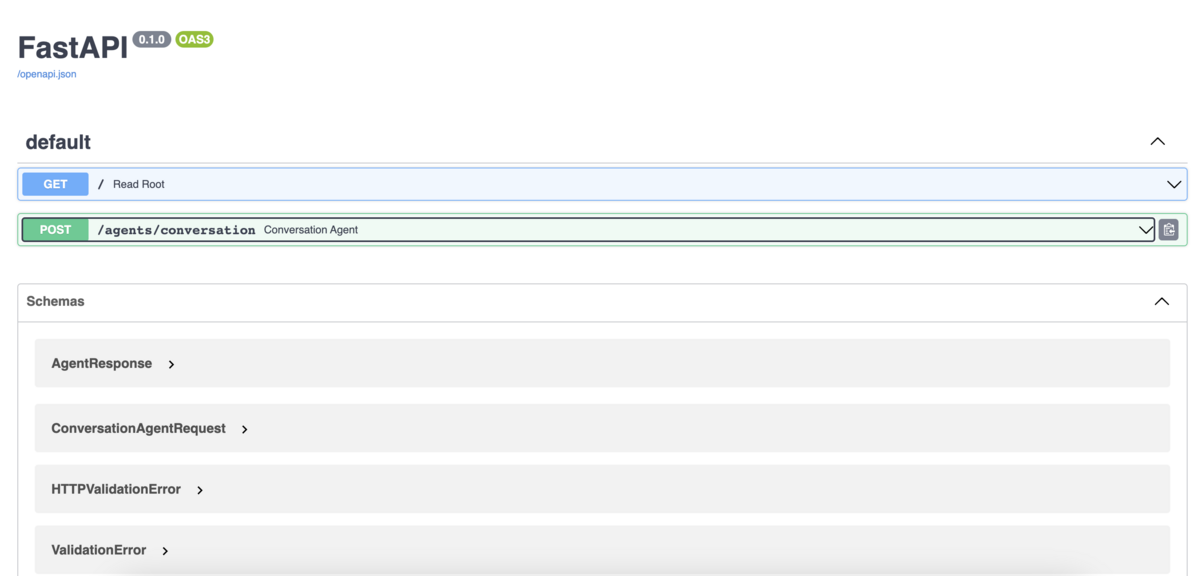
Requestはこちら。
Responseはこちら。

APIの動作確認
APIの動作確認は「Try it out」のボタンからcurlをパッと叩くことができます。

適当なメッセージを入力して、エラーにならずにReponseが返ってくれば成功です。
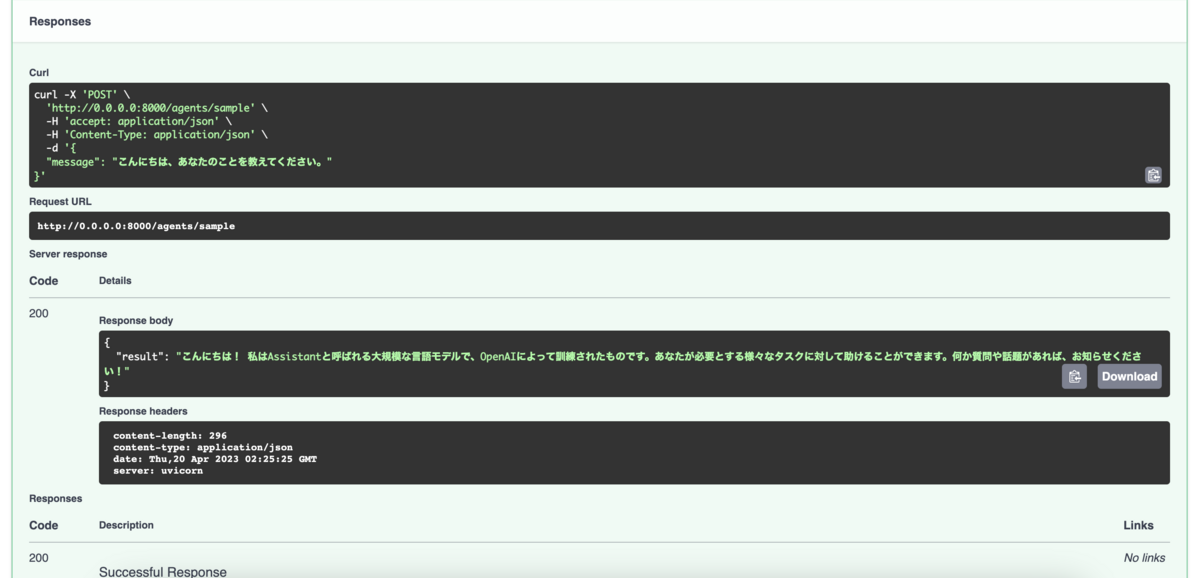
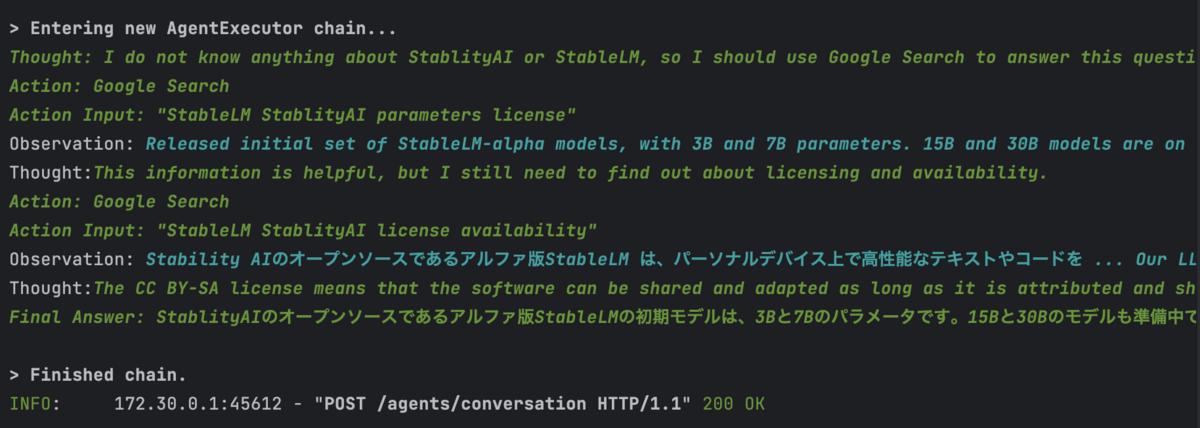
せっかくGoogle検索のToolを組み込んだので、ChatGPTが学習していないであろう最近の出来事に関して質問してみましょう。
Q: StablityAIが2023/04に発表した新しいLLMである「StableLM」について、使用可能なパラメータ数の選択肢やライセンス体系について教えてください。
A: StablityAIのオープンソースであるアルファ版StableLMの初期モデルは、3Bと7Bのパラメータです。15Bと30Bのモデルも準備中です。また、StableLMはCC BY-SA-4.0ライセンスでリリースされており、共有や適応には同じライセンスが必要です。

ログを見るとGoogle SearchのToolを使う判断をして結果を返そうとしていることが分かると思います。
Unity側のAPI呼び出しの実装
Unity側の実装はAPIが叩ければ好きに実装して良いです。
あまり参考にはならないですが、自分はHttpWebRequest、Newtonsoft.Jsonを使って、自前のエラーハンドリングライブラリを使ってエラー処理やリトライ処理等を組み込んだ実装が好みなので、こちらのように実装をしています。
FastAPIで自分で作成したAPI仕様に合わせて、Request bodyのJSONを作成し、Response bodyのJSONをでシリアライズして結果を取り出します。
もちろんUnityWebRequestやJsonUtilityなどを使っても実装はできますのでお好みで実装してください。
結果
仕上げに、DockerでFastAPIのサーバーを立ち上げている状態で、UnityからAPIを叩いてみましょう。
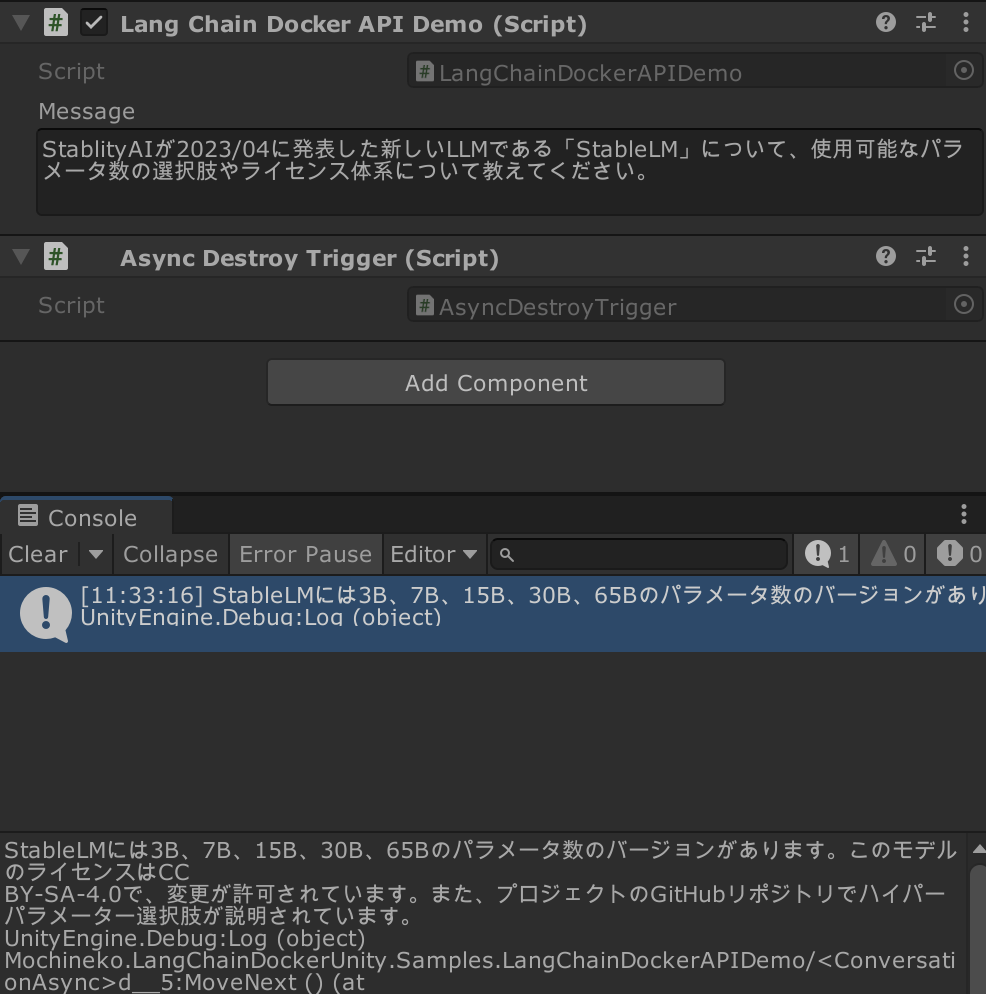
想定しているようにResponseが返ってくれば成功です。
まとめ
以上で説明した構成で、UnityからLangChainをFastAPIのAPIサーバー経由できました。
このような構成を取るメリットとデメリットを確認しておきましょう。
メリット
- 複雑な振る舞いをするAgentをLangChainを利用して手軽に用意できる
- LLMの差し替えが容易
- API KeyなどをUnity側で持たなくて良いので、それらを不正利用されるリスクが少ない
- Prompt Injection対策をサーバー側でできる
- 1サーバー v.s. 複数Unityクライアントの構成で、複数Unityクライアント間での会話のコンテキストの共有ができる
- FastAPIはサーバーサイド初心者でも触りやすい
デメリット
- LangChainで複雑なAgentを組むとレスポンスの遅延が悪くなりやすい(Stream化もしづらい)
- セットアップ次第では複雑なAgentは動作が不安定になることもある
- (当然だが)サーバーサイドの技術知識が一定必要になる
- (個人的には)Pythonで複雑な仕様のライブラリを触るのが大変
また、今回は省いていますが、実際にサービスに乗せるとなると当然サーバー側の認証・認可やセキュリティ、データベース、デプロイなどの準備も必要になりますので、今回紹介したソースコードはあくまでLocalでの検証にとどめて参照してください。
おわりに
以上簡単にですが、FastAPIを使ってLangChainの機能をWebAPI経由でUnityから使用するまでの流れをざっと解説しました。
今回初めてFastAPIを触ったのですが、APIの定義方法が分かりやすい上にOpenAPIのドキュメントを自動生成してくれるのがとても便利に感じました。
Unityメインで開発している自分でも短時間で構築ができたので、サーバーサイド開発未経験の方でも比較的トライしやすいのではないかと思います。
自分は昨年末に趣味でサーバーサイドの勉強をしていて基本的な流れが分かっていたのもありますが。
LangChainはかなり開発のペースが早く、最近話題の自律駆動Agentなどの実装例もあったりしますので、LLMの応用で具体的にどんなことができるのかの最前線が知りたい方は自分で触ってみることをお勧めします。
各種AgentやTool、VectorStoreなどを見ると応用の幅も広がるかと思います。
実際のプロダクトに組み込むにあたってはUnityから直接ChatGPTなどのAPIを叩くことももちろん可能ですので、
メリット・デメリットを見てユースケースに合わせて選択できればと。
個人的にはこれを機にサーバーサイドの認証まわりやクラウドへのホスティングなどにも挑戦してみようかと考えています。