Rust の Stream の基本的な取り回しを理解する

こんにちは、エンジニアの渡辺(@mochi_neko_7)です。
今回は Rust における Stream の基本的な取り回しを紹介します。
Anthropic の Claude API の Rust Client を書いていた際に Streaming API の対応をしていたところ、自身が Rust の Stream をちゃんと理解していなかったことに気づき勉強し直していました。
ところが日本語で解説している記事をあまり見かけなかったため、本記事で自分の理解している範囲で基礎的な内容を整理して紹介したいと思います。
もし間違った記述等ありましたらご指摘いただけますと幸いです。
環境
- Rust:
v1.76.0 - futures_core:
v0.3.30 - async_stream:
v0.3.5 - futures_util:
v0.3.30 - tokio_stream:
v0.1.15
Rust の Stream
そもそも Rust の Stream はどんなものか、という基礎の解説は英語ですが下記にあります。
こちらを参考にしていただきつつ、ここでは次の二点を押さえておきましょう。
- 非同期版 Iterator としての Stream
- Poll の扱い
1. 非同期版 Iterator としての Stream
Rust の Iterator は下記のような trait で定義されています。
pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; }
Option<Self::Item> の戻り値は値を返せる場合には Some(Item) を、 Iterator の終端に達して値を返せない場合には None を返すものです。
他言語だと boolean と nullable の組み合わせでこれらを表現したりしますが、Rust では Option でシンプルに表現できます。
一方、Stream の trait の定義を見てみると、非同期システムの都合で見かけが変わっている点はあるものの基本的には同じ形式をしていることがわかります。
pub trait Stream { type Item; fn poll_next( self: Pin<&mut Self>, cx: &mut Context ) -> Poll<Option<Self::Item>>; }
Stream in futures_core::stream - Rust
本題にあまり関係ない size_hint は省略しています。
実際、futures_util の StreamExt を利用すると
use futures_util::StreamExt; while let Some(item) = stream.next().await { // item の処理 }
のように Iterator に .await を付けたような格好で呼び出すことができます。
2. Poll の扱い
Poll は下記で定義されています。
pub enum Poll<T> { Ready(T), Pending, }
状態として二種類あります。
Poll::Ready(T): 値Tを返す準備ができている状態Poll::Pending: 値を返す準備ができていない状態
Stream の場合は T に Option<Self::Item> を指定するので、状態は次の三種類を取ります。
Poll::Ready(Some(T)): 値Tを返す準備ができている状態Poll::Ready(None): Stream の終端に達した状態Poll::Pending: 値を返す準備ができていない状態
Stream を読むだけの場合には StreamExt の next().await を呼ぶかと思いますので、Stream trait を自分で実装する場合以外は Poll の細かい取り扱いは気にしなくて済みます。
Stream の周辺 crate
Stream は Rust のコアには最低限の trait しか用意されておらず、さまざまな便利機能は現在では別 crate で提供されています。
1. futures_core
Stream の定義は futures_core crate から提供されています。
他 crate もこの Stream を利用していますし Stream を Re-export してくれている場合も多いので、以下の拡張 crate を利用する際には不要な場合もあります。
2. async_stream
async_stream は標準では提供されていない yield 構文による Stream の生成を、stream! マクロによってサポートしています。
use async_stream::stream; use futures_core::stream::Stream; fn zero_to_three() -> impl Stream<Item = u32> { stream! { for i in 0..3 { yield i; } } }
ちなみに Iterator から Stream を生成したい場合には以下で紹介する crate の futures_util::stream::iter() や tokio_stream::iter() などを利用できます。
3. futures_util
futures_util は Stream を含む Rust の非同期 API の拡張機能を提供します。
将来的に安定した機能は futures_core に統合されるものらしいです。
特に重要なのが StreamExt で、非同期 API .await で呼び出せる StreamExt::next() や StreamExt::map() 、StreamExt::filter() などの Iterator と同様の Adapter 系機能などを提供します。
StreamExt in futures_util::stream - Rust
先にも使用例を書きましたが、futures_util::StreamExt の利用イメージは下記になります。
use futures_util::StreamExt; async fn some_function() { let mut stream = futures_util::stream::iter(vec![0, 1, 2]); while let Some(value) = stream.next().await { println!("Got {}", value); } }
ただし、futures_util::StreamExt::next() は非同期ではありますがシングルスレッドで動作するため、マルチスレッドを利用したい場合には tokio-stream などマルチスレッドに対応している非同期バックエンドによる実装を利用した方が良い場合もありますので、ユースケースに合わせて選択してください。
4. tokio-stream
tokio の非同期バックエンドと連携した運用をする際には、tokio-stream で提供されている拡張機能を利用することもできます。
futures_util::StreamExt の代わりに tokio_stream::StreamExt を使用するイメージです。
use tokio_stream::StreamExt; async fn some_function() { let mut stream = tokio_stream::stream::iter(vec![0, 1, 2]); while let Some(value) = stream.next().await { println!("Got {}", value); } }
ただし、現行バージョンでは poll_next_unpin など futures_util::StreamExt ではサポートしていても tokio_stream::StreamExt ではサポートされていない機能などもありますので注意が必要です。
使い分け
futures_util と tokio_stream はどちらも StreamExt を提供していますが、非同期バックエンドが異なるためユースケースに応じて使い分けが必要です。
futures_util: 標準の非同期 API (futures_core) バックエンド、シングルスレッドtokio_stream:tokioバックエンド、マルチスレッド対応
他の非同期バックエンドを利用する際には対応するものを探してみてください。
Stream の変換
Stream の変換は StreamExt の Adapter で済む場合もありますが、バッファリングをして最適化した場合など自分で Stream の変換処理を書いた方がいいケースもあります。
Stream の取り回しの確認も兼ねて、例として reqwest、つまり HTTP のレスポンスを Byte の Stream として受け取り、行ごとのテキストに分割して Stream として提供することを考えてみましょう。
この場合、Byte 配列をバッファリングしつつ改行コードを見つけたら Chunk を返す、という Stream の実装をします。
use std::pin::Pin; use std::task::{Context, Poll}; use bytes::{Buf, BytesMut}; use futures_core::Stream; use pin_project::pin_project; // Stream の処理のエラーの定義 (thiserrorを利用) #[derive(Debug, thiserror::Error)] enum LineStreamError { #[error("Failed to read reqwest stream: {0:?}")] ReqwestError(#[from] reqwest::Error), #[error("Failed to decode chunk to UTF-8 string: {0:?}")] StringDecodingError(#[from] std::string::FromUtf8Error), } // Stream の Item の定義 type LineStreamResult = Result<String, LineStreamError>; // 自作の行ごとのテキストの Stream の定義 #[pin_project] struct LineStream<S> where S: Stream<Item = ReqwestStreamItem> + Unpin, { #[pin] stream: S, // 元の Stream buffer: BytesMut, // bytes の可変長バッファ } // reqwest の Response Stream の Item type ReqwestStreamItem = Result<bytes::Bytes, reqwest::Error>; // 初期化メソッドの定義 impl<S> LineStream<S> where S: Stream<Item = ReqwestStreamItem> + Unpin, { fn new(stream: S) -> Self { LineStream { stream, buffer: BytesMut::new(), } } } // 目的の Stream trait の実装 impl<S> Stream for LineStream<S> where S: Stream<Item = ReqwestStreamItem> + Unpin, { type Item = LineStreamResult; // 最終的に欲しい Item の型をここで指定する fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_>, ) -> Poll<Option<LineStreamResult>> { let mut this = selft.project(); // Unpin loop { // バッファに改行を含む場合 if let Some(position) = this .buffer .iter() .position(|b| *b == b'\n') { // position より手前の bytesを取り出す let line = this.buffer.split_to(position); // position にある改行はスキップする this.buffer.advance(1); // bytes を UTF-8 String にデコードする let line = String::from_utf8(line.to_vec()) .map_err(StreamLineError::StringDecodingError)?; // デコードした文字列を返す return Poll::Ready(Some(Ok(line))); } // 内部の Stream の読み込み match this .as_mut() .stream .poll_next(cx) { // bytes を受け取った場合 | Poll::Ready(Some(Ok(chunk))) => { // バッファに bytes を格納する this.buffer.extend(&chunk); // 手前の改行を取り出す処理に入るまで loop を継続する }, // Error が返ってきた場合 | Poll::Ready(Some(Err(error))) => { return Poll::Ready(Some(Err( StreamLineError::ReqwestError(error), ))); }, // Stream の終端に達した場合 | Poll::Ready(None) => { // バッファが空の場合は何もしない return if this.buffer.is_empty() { Poll::Ready(None) // バッファにデータが残っている場合は処理を試みる } else { let line = this.buffer.split_off(0); let line = String::from_utf8(line.to_vec()) .map_err(StreamLineError::StringDecodingError)?; Poll::Ready(Some(Ok(line))) }; }, // 待機中の場合はそのまま | Poll::Pending => return Poll::Pending, } } } }
利用している crate は下記になります。
futures_corereqwestbytespin_projectthiserror
まず、#[pin_project]、#[pin]、let mut this = selft.project(); などは元の Stream を Unpin するためのものです。
futures_util::StreamExt には StreamExt::poll_next_unpin という便利メソッドがあるのでそちらを使うと楽ですが、使わない場合には pin_project crate を使って Unpin を実装できます。
StreamExt in futures_util::stream - Rust
今回の変換処理の主題はテキストの bytes を読み込んでバッファに溜めつつ、改行を見つけた場合に行分のテキストを取り出したいものでした。
元の Stream を読み込んでバッファに溜めていく処理は
// 内部の Stream の読み込み match this .as_mut() .stream .poll_next(cx) { ... }
のブロックで実装しています。
そして、
// バッファに改行を含む場合 if let Some(position) = this .buffer .iter() .position(|b| *b == b'\n') { ... }
の処理で改行コード \n を探索し、発見した場合にはそれをテキストに変換して結果を返します。
実際に使用するイメージは下記になります。
use tokio_stream::StreamExt; use xxx::LineStream; #[tokio::main] async fn main() -> anyhow::Result<()> { let stream = reqwest::get("http://httpbin.org/ip") .await? .bytes_stream(); let mut line_stream = LineStream::new(stream); if let Some(line) = line_stream.next().await { println!("Line: {:?}", line); } Ok(()) }
ライブラリで Stream を利用する際に気をつけたいこと
アプリケーションとして Stream を扱う場合にはアプリケーション全体で利用する非同期バックエンドに準拠して実装をすれば良いですが、ライブラリとして Stream を扱う場合にはライブラリ利用者がどの非同期バックエンドを使うのか想定することはできません。
ライブラリ内部で特定の非同期バックエンドに依存した処理を他でしていない場合には、使用する crate を適切に選択肢、なるべく依存関係を少なく(つまりバイナリのサイズを小さく)したいでしょう。
その場合、futures_core crate のみで実装し、futuers_util、tokio_stream の具体の拡張を利用しないのも選択肢の一つです。
具体例として自分が開発している Claude API の Rust Client
では Streaming モードの API もサポートしていますが、API としては
pub async fn create_a_message_stream( &self, request_body: MessagesRequestBody ) -> MessagesResult<impl futures_core::stream::Stream<Item = ChunkStreamResult>>
のように futures_core のみ使用し、README や examples では futures_util と tokio_stream の両方を使ったサンプルを提供しています。
とはいえ futures_util に関しては将来的にはコアに含められる可能性もあるため、どこまで利用すべきかはプロジェクト次第かと思います。
まとめ
以上で紹介した内容を端的にまとめると下記になります。
- Stream は非同期版の Iterator
next()やmap()、filter()などの拡張機能は、futures_utilやtokio_streamのStreamExtなどで提供されている- ユースケースに応じてコア crate(
futures_core)、拡張 crate (async_stream、futures_util、tokio_streamなど)を使い分ける - Stream の変換処理は Adapter だと難しい(あるいは効率が悪い)場合でも、 Stream trait を自分で実装すれば可能
- Stream を利用したライブラリを作成する場合には
futures_coreのみで実装するのも選択肢の一つ
おわりに
自分で実際に Stream を利用したライブラリの開発を通じて理解した内容を基に、Stream の基本的な取り回しを紹介しました。
もっと深掘りをすれば TryStream や cx: &mut Context<'_> って何?といった話もありそうですが、今回はもっともシンプルに Stream を扱う際に必要になる話に限定しました。
Rust の Stream は高度に抽象化されているのもあり、ちゃんと理解した後だとかなり扱いやすいなと思いました。
Rust の入門ドキュメントには Stream の解説がなかった気がしますが、似たような仕組みの Channel より扱いやすいので使えて損はないでしょう。
Claude の API の Rust Client の Streaming API の実装も参考にしていたければと思います。
Rust で何かの crate の API で提供される Stream を利用したい、その Stream を扱いたい形式に変換したい、あるいは Stream を使った API を含むライブラリを開発したい方に参考になれば幸いです。
XR Interaction Toolkitをマウス入力に対応させる

XR Interaction ToolkitはUnity公式が提供するパッケージの一つです。その中には、XR向けのインタラクションを実装する為に必要なコンポーネントが一通り揃っています。
私が認識している限り、今までのUnityのインタラクション事情は、UIに対してはuGUIという強力な仕組みが用意されていたものの、3Dオブジェクトに対してのインタラクションは基本的な機能しか提供されていませんでした。それだけ各アプリケーションにおいての事情が異なるという事もあるのでしょうが、このためにそれぞれの開発者が独自にEventSystemを拡張したり、Raycastした結果を捏ね繰り回すコードを書いてやる必要がありました。(少なくとも私たちは書いていました)
そんな中登場したXR Interaction Toolkitは、触れ込みこそXR向けですが、内部に3Dオブジェクトに対するインタラクションを行うための一連の仕組みを持っています。これはXRデバイスに依存しないレベルで抽象化されており、非XRアプリでも使用することが十分可能です。しかも、以下のような素直に実装すると意外と面倒な機能も最初から持っています。
- ワールド空間に存在するUIと競合しない
- 複数個のInteractorが同時に触っても状態管理が破綻しない
また、XRアプリを非XRデバイスに対応したいとなった時も、インタラクションの仕組み自体を改修する必要がないというのは大きな強みになります(当然、別の操作体系で同じ体験を提供するための改修は必要ですが)。
ただし、現時点では非XRデバイスは残念ながら公式サポートされておらず、インポートしてすぐに非XRアプリに組み込む事はできません。パッケージ内にはInputSystemの入力をInteractorが使う形に変換するControllerというクラスが用意されているのですが、このクラスが現時点ではXRの各種トラッキングデバイス向けのものしか用意されていません。
しかし、目的に合わせたControllerを自作することは、実は非常に容易です。
そこで、今回はマウスを使ったControllerを例として実装してみました。
環境
- Unity 2022.3.19f1
- XR Interaction Toolkit 2.5.2
コードサンプル
using UnityEngine; using UnityEngine.InputSystem; using UnityEngine.XR; using UnityEngine.XR.Interaction.Toolkit; namespace MyApp.Interaction { public class MouseController : XRBaseController { [SerializeField] private Camera controllerCamera; [SerializeField] private InputActionProperty mousePosition; [SerializeField] private InputActionProperty leftClick; private Transform controllerCameraTransform; private Transform parentTransform; private void Start() { if (controllerCamera == null) { Debug.LogWarning("CameraBaseController: No camera assigned. Disabling."); enabled = false; } controllerCameraTransform = controllerCamera.transform; parentTransform = transform.parent; } protected override void UpdateTrackingInput(XRControllerState controllerState) { base.UpdateTrackingInput(controllerState); if (controllerState == null) { return; } controllerState.isTracked = mousePosition.action.enabled; var screenPos = mousePosition.action.ReadValue<Vector2>(); var origin = controllerCamera.ScreenToWorldPoint(new Vector3( screenPos.x, screenPos.y, controllerCamera.nearClipPlane)); var forward = (origin - controllerCameraTransform.position).normalized; var upward = controllerCameraTransform.up; ConvertWorldToLocal(ref origin, ref forward, ref upward); controllerState.position = origin; controllerState.rotation = Quaternion.LookRotation(forward, upward); controllerState.inputTrackingState = InputTrackingState.Position | InputTrackingState.Rotation; } private void ConvertWorldToLocal(ref Vector3 origin, ref Vector3 forward, ref Vector3 upward) { if (parentTransform == null) { return; } origin = parentTransform.InverseTransformPoint(origin); forward = parentTransform.InverseTransformDirection(forward); upward = parentTransform.InverseTransformDirection(upward); } protected override void UpdateInput(XRControllerState controllerState) { base.UpdateInput(controllerState); if (controllerState == null) { return; } controllerState.ResetFrameDependentStates(); var clickActionValue = leftClick.action.ReadValue<float>(); controllerState.selectInteractionState.SetFrameState( clickActionValue > 0.5f, clickActionValue); } } }
オリジナルのControllerは、 XRBaseController を継承したクラスで UpdateTrackingInput(XRControllerState) と UpdateInput(XRControllerState) をオーバーライド実装してやれば比較的簡単に作ることができます。
UpdateTrackingInput(XRControllerState) は、コントローラーの姿勢を更新する為のメソッドです。controllerState に対して、現在の座標と向きを入れてやります。ただし、姿勢データはローカル座標系で処理されるので、それを考慮して変換してやる必要があります。
UpdateInput(XRControllerState) は、コントローラーのSelect、Activate入力の状態を更新する為のメソッドです。controllerState.selectInteractionStateを更新してやれば、Select処理、いわゆる掴む処理を実装出来ます。
実装したコンポーネントの利用
上で実装したコンポーネントを、XR Interaction Toolkitに入っているInteractorと同じGameObjectにアタッチすることで動作させることが可能です。スクリプトで定義したカメラとマウス入力を指定してあげてください。マウス入力に関しては、Input Systemのパッケージにデフォルトで含まれているDefaultInputActionsに含まれているものを使えば問題ないかと思います。


(Input Action ManagerにDefaultInputActionsを忘れずに設定してください。)
最終的なセットアップの形は、XR Interaction Toolkitのサンプルに含まれる、XR Interaction Setupを参考にした場合、以下のようになるかと思います。各アプリの事情に合わせて柔軟に変更してください。
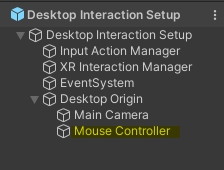
以下は動作している様子です。灰色のオブジェクトにXR Simple Interactableをアタッチし、受け取ったイベントをログ出力しています。

Cloudflare Workers + Honoの環境構築からデプロイまでが簡単すぎた
はじめに
こんにちは、エンジニアのクロ(@kro96_xr)です。
先日他社のエンジニアの方と話す機会があったのですが、そこでHono(炎)というフレームワークを知りました。
元々はCloudflare Workersに特化したWebアプリを作るために作られたものとのことで、ちょうどCloudflare Workersも触ってみたかったので試してみました。
その結果、あまりにも爆速で環境構築とデプロイが完了し、タイトルの感想を抱きましたのでご紹介します。
Honoの特徴などは開発者の方の記事にて詳しく書かれておりますのでそちらもご覧ください。
サインアップからデプロイまで
Cloudflareのアカウント作成
以下のページからサインアップを行います。ここで登録した認証情報を後ほど使います。
Cloudflare Workers | サーバーレスアプリケーションを構築 | Cloudflare
プロジェクトの作成
Cloudflare Workersのプロジェクト作成のためにはWranglerというコマンドラインツールを使います。
npm install -g wrangler
バージョン3.34.2がインストールされました。
wrangler --version ⛅️ wrangler 3.34.2 -------------------
CLIからCloudflareにログインします。 以下を実行するとブラウザで認証画面が表示されます。
wrangler login
プロジェクトを作成します。
wrangler init {プロジェクト名}
コマンドを実行すると不足しているパッケージのインストール可否が聞かれたのち、アプリケーション作成のためにいくつか質問されます。
今回はwebアプリをHonoで実装して…
╭ Create an application with Cloudflare Step 1 of 3 │ ├ In which directory do you want to create your application? │ dir ./{プロジェクト名} │ ├ What type of application do you want to create? │ type Website or web app │ ├ Which development framework do you want to use? │ framework Hono │ ├ Continue with Hono via `npx create-hono@0.5.0 {プロジェクト名} --template cloudflare-workers` │ Need to install the following packages: create-hono@0.5.0 Ok to proceed? (y) y create-hono version 0.5.0
npmでパッケージ管理して、git管理もして…
Configuring your application for Cloudflare Step 2 of 3 │ ├ Installing @cloudflare/workers-types │ installed via npm │ ├ Adding latest types to `tsconfig.json` │ added @cloudflare/workers-types/2023-07-01 │ ├ Do you want to use git for version control? │ yes git │ ├ Committing new files │ git commit │ ╰ Application configured
Cloudflareにデプロイをします。
╭ Deploy with Cloudflare Step 3 of 3 │ ├ Do you want to deploy your application? │ yes deploy via `npm run deploy` │ ├ Logging into Cloudflare checking authentication status │ logged in │ ├ Selecting Cloudflare account retrieving accounts │ account {アカウント名} Account │ ├ Deploying your application │ deployed via `npm run deploy` │ ├ SUCCESS View your deployed application at https://{プロジェクト名}.{アカウント名}.workers.dev │ │ Navigate to the new directory cd {プロジェクト名} │ Run the development server npm run dev │ Deploy your application npm run deploy │ Read the documentation https://developers.cloudflare.com/workers │ Stuck? Join us at https://discord.gg/cloudflaredev │ ├ Waiting for DNS to propagate │ DNS propagation complete. │ ├ Waiting for deployment to become available │ deployment is ready at: https://{プロジェクト名}.{アカウント名}.workers.dev │ ├ Opening browser │ ╰ See you again soon!
これでプロジェクト作成とHello Worldのデプロイが終わりました。 コマンドラインに表示されたURLにアクセスするとHello Hono!と返ってきます。

流石に爆速すぎますね。
Honoで実装されているコードも見てみます。
デフォルトのindex.tsは以下のようになっています。シンプルですね。
import { Hono } from 'hono' const app = new Hono() app.get('/', (c) => { return c.text('Hello Hono!') }) export default app
適当にコードを修正して再デプロイしてみます。
import { Hono } from 'hono' const app = new Hono() app.get('/', (c) => { return c.text('Hello World!') }) export default app
デプロイはnpm run deployを叩くだけです。
プロジェクト作成時にpackage.jsonを更新してくれていますね。
{ "scripts": { "dev": "wrangler dev src/index.ts", "deploy": "wrangler deploy --minify src/index.ts" }, "dependencies": { "hono": "^4.1.0" }, "devDependencies": { "@cloudflare/workers-types": "^4.20240314.0", "wrangler": "^3.32.0" } }

簡単すぎる。
何かを新しく開発する時の環境構築は大体面倒だと思っているのでとても助かりますね。(個人の感想です)
おわりに
これまでサーバーレスはAWS Lambdaしか触ったことがなかったのですが、思った以上に入門ハードルが低くどちらも触れるようにしておきたいなと思いました。
特に個人開発や小規模開発においてちょっとした処理を書きたい場合は今回の構成の方がスピード感を持って開発できる可能性もありそうです。
この記事だとまだHonoそのものに入門できていないので、引き続きキャッチアップしていきたいと思います。
過去にLambda関連で執筆した記事
Github ActionsとSlackとLambdaを連携して社内向け署名付きURLを生成する - Activ8 Tech Blog
ServerlessFrameworkを使ってChatGPT APIを使ったLineBotを作る - Activ8 Tech Blog
参考にさせていただいた記事
RestAPIを実装しようかと思ったら既に素晴らしい記事がありました
Hono + Cloudflare Workers で REST API を作ってみよう
Cloudflare Workersの特性について深掘りされていて勉強になりました。
【ふーん、”エッジ”じゃん】Cloudflare Workersが0ms Cold Startsを実現するカラクリ
Reactもいけるのか…ということで試してみたいです。
日付ライブラリTempoを触ってみた(date-fnsと比較)

はじめに
こんにちは、フロントエンドエンジニアの堀江(@nandemo_3_)です。
先日、JavaScriptの新たな日付ライブラリがTempoがリリースされました。
2023/2/26にv0.0.13がリリースされたばかりです。
リリース3日後でStar数が1700になっており、今後の伸びが期待されるところです。
お決まりの既存の類似ライブラリとStar数を比べた画像はこちらです。
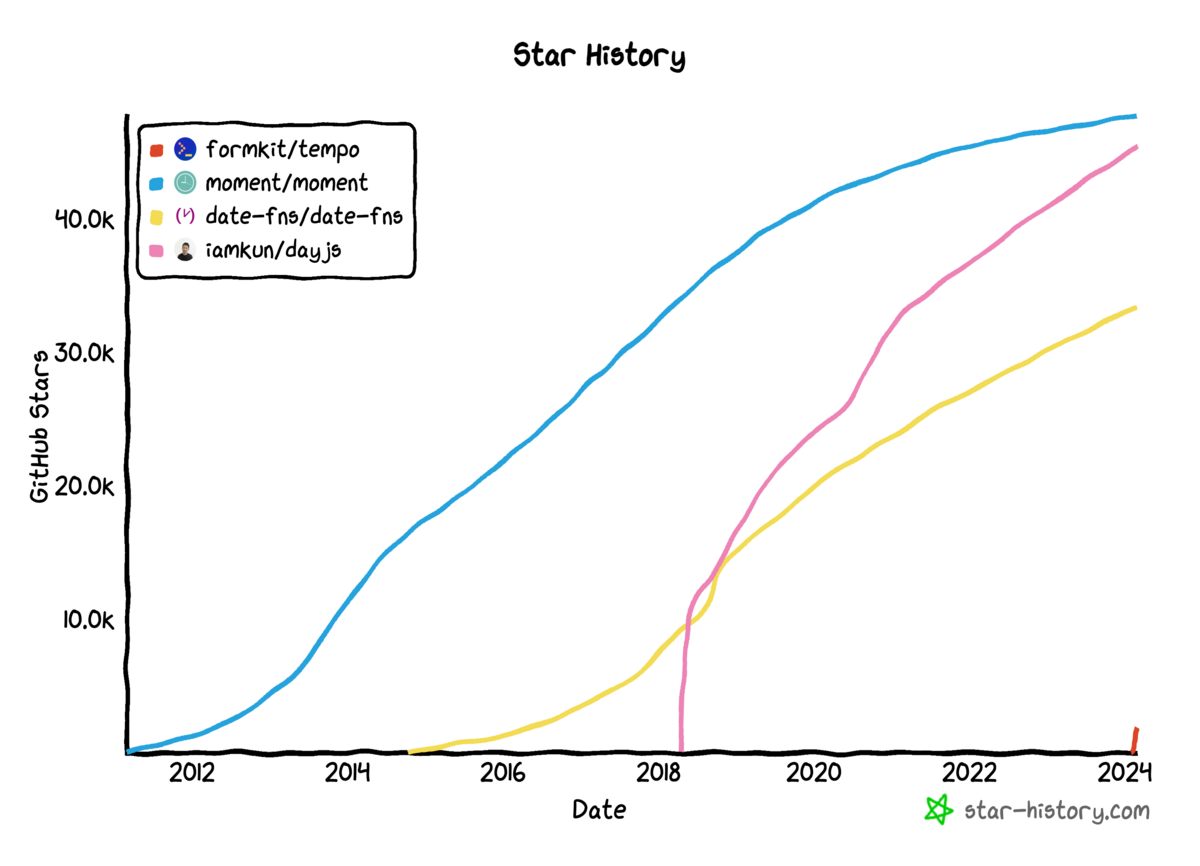
あまり情報がないので、触りながら色々試していこうと思います。
Tempoの特徴
Tempoは、JavaScriptの日付と時刻のライブラリの誇り高き伝統の中の新しいライブラリです。
moment.js、day.js、date-fnsなどにインスパイアされたTempoは、可能な限り小さく使いやすいように一から作られています。
Tempoは、ネイティブのDateオブジェクトを扱うためのユーティリティ・コレクションと考えるのが最適です。
Tempoは、JavaScriptのIntl.DateTimeFormatを利用して、タイムゾーンオフセットやロケールを意識した日付フォーマットのような複雑なデータを抽出し、日付のフォーマット、解析、操作を行うシンプルなAPIを提供します。
(ドキュメントから抜粋)
セットアップ
早速プロジェクト作成していきます。
今回はBunを使っていきます。
結論、BunはNode.jsと互換性があるので、Tempoも問題なく使えました。
$ mkdir tempo-sample $ cd tempo-sample $ bun init bun init helps you get started with a minimal project and tries to guess sensible defaults. Press ^C anytime to quit package name (tempo-sample): entry point (index.ts): Done! A package.json file was saved in the current directory. + index.ts + .gitignore + tsconfig.json (for editor auto-complete) + README.md To get started, run: bun run index.ts
ライブラリのインストール
続いて、Tempoをインストールしていきます。
比較のため、date-fnsもインストールします。
Tempoは軽量と言われていますが、確かにインストールがdate-fnsよりも半分の時間で完了しました。
Tempoの場合
$ bun install @formkit/tempo bun add v1.0.7 (b0393fba) installed @formkit/tempo@0.0.13 1 package installed [947.00ms]
date-fnsの場合
$ bun install date-fns bun add v1.0.7 (b0393fba) installed date-fns@3.3.1 1 package installed [1.85s]
2種類のフォーマットタイプ
フォーマットはformat関数を使います。
そして、フォーマットタイプがFormat stylesとFormat tokensの2つ用意されています。
引数の値を変えるだけで、フォーマットタイプを選ぶことができます。
Format styles
Format stylesは、Intl.DateTimeFormatを用いて、言語に依存した日付、時刻を取得することができます。
format関数の第2引数fomatにfullやlongなどを指定すると対応したフォーマットの日付が出力されます。
そして、第3引数localeに言語タイプを指定すると、その言語に合わせたフォーマットとなります。
日本語に対応しているのは嬉しいですね。
import { format } from "@formkit/tempo";
const date = new Date();
// 同じ結果
format(date, { date: "full" }, "en"); // Thursday, February 29, 2024
format(date, "full", "en"); // Thursday, February 29, 2024
// 日本語
format(date, "full", "ja"); // 2024年2月29日 木曜日
format(date, "long", "ja"); // 2024年2月29日
format(date, "short", "ja"); // 2024/02/29
また、時刻を表示する場合は、第2引数fomatをobject型にします。
{ date: "long", time: "short" }のようにすれば、日付と時刻が出力されます。
import { format } from "@formkit/tempo";
const date = new Date();
format(date, { date: "long", time: "short" }, "en"); // February 29, 2024 at 9:08 PM
format(date, { date: "long", time: "short" }, "ja"); // 2024年2月29日 21:03
Format tokens
続いて、Format tokensは、表示したいフォーマットが決まっている場合に使います。
date-fnsと同じですね。
Tempoの場合
format(date, "YYYY-MM-DD", "en"); // 2024-02-29
date-fnsの場合
import { format } from "date-fns";
format(new Date(), "yyyy年MM月dd日 HH:mm"); // 2024年02月29日 21:27
タイムゾーン設定
Tempoはデフォルトで、タイムゾーンを設定できます。
date-fnsはdate-fns-tzをいう別のライブラリをインストールする必要があり一手間必要ですが、Tempoは追加プラグインなしです。
これは地味に大きいのではないでしょうか。
import { format } from "@formkit/tempo";
const date = new Date();
// February 29, 2024 at 4:42 AM
format({
date: date,
format: { date: "long", time: "short" },
locale: "en",
tz: "America/Los_Angeles",
})
// 2024年2月29日 21:42
format({
date: date,
format: { date: "long", time: "short" },
locale: "ja",
tz: "Asia/Tokyo",
})
文字列の日付のフォーマット
最後に、ISOとUTCの文字列をフォーマットをしてみました。
ISOは問題なく変換されましたが、UTCはエラーとなりました。
import { format } from "@formkit/tempo";
const isoDate = new Date().toISOString(); // 2024-02-29T13:04:11.530Z
const utcDate = new Date().toUTCString(); // Thu, 29 Feb 2024 13:04:11 GMT
// February 29, 2024 at 5:07 AM
format({
date: isoDate,
format: { date: "long", time: "short" },
locale: "en",
tz: "America/Los_Angeles",
});
// error: Non ISO 8601 compliant date (Thu, 29 Feb 2024 13:08:06 GMT).
format({
date: utcDate,
format: { date: "long", time: "short" },
locale: "ja",
tz: "Asia/Tokyo",
});
TempoはISO 8601に準拠した日付のみフォーマットするようです。
ドキュメントを調べたらコメントアウトでしれっと書いてありました。
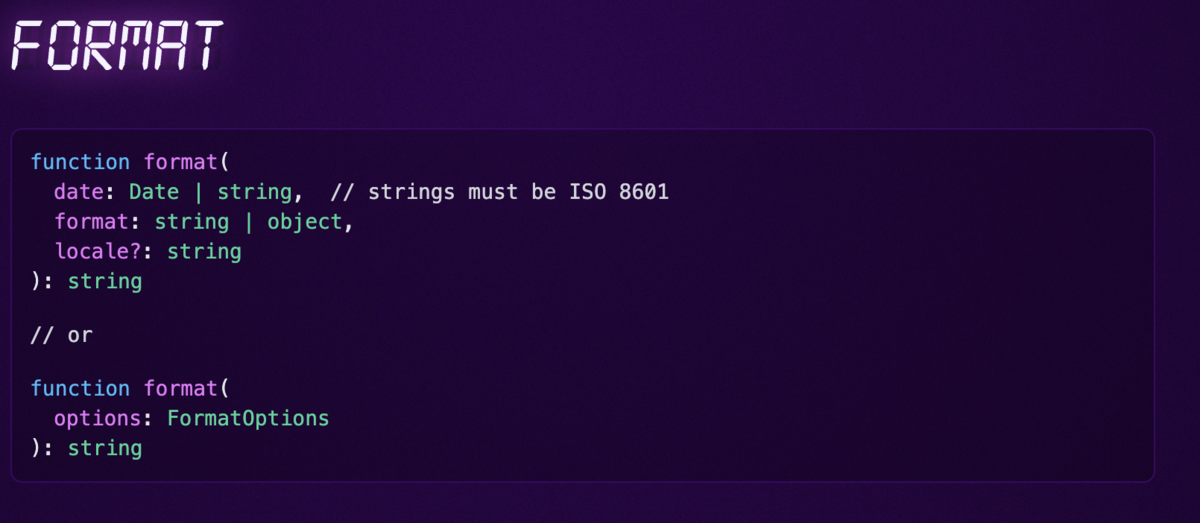
parse関数
そういったISO 8601以外の日付文字列をフォーマットする場合にparse関数があります。
フォーマットしたい日付文字列とフォーマットを一致させると、ISO 8601に変換してくれます。
例えば、UTCの場合Thu, 29 Feb 2024 13:43:12 GMTなので、ddd, DD MMM YYYY HH:mm:ssとすればOKです。
ただ、タイムゾーンの反映はされませんでした。
import { parse, format } from "@formkit/tempo";
const isoDate = new Date().toISOString(); // 2024-02-29T13:43:12.646Z
const utcDate = new Date().toUTCString(); // Thu, 29 Feb 2024 13:43:12 GMT
// ISO
// 2024年2月29日 22:42
format({
date: isoDate,
format: { date: "long", time: "short" },
locale: "ja",
tz: "Asia/Tokyo",
});
// UTC
// 2024年2月29日 13:41
format({
date: parse(utcDate, "ddd, DD MMM YYYY HH:mm:ss"),
format: { date: "long", time: "short" },
locale: "ja",
tz: "Asia/Tokyo",
});
最後に
以上がTempoのざっくり使用感レビューでした。
詳しく仕様を知りたい方は、ドキュメントをご覧ください。
感想としては、言語タイプやタイムゾーンの設定が簡単で、date-fnsよりもシンプルなコードだったので、非常に使い勝手の良いライブラリでした。
多言語対応しているアプリケーション開発で、日付フォーマットやタイムゾーンの指定が地味に面倒くさいのではないかと思うので、
こういったパラメータ1つで対応可能なのは、エンジニアにとって非常にありがたいと思いました。
最後まで、読んでくださりありがとうございました。
Bitbucket PipelinesのWindowsセルフホストランナーを、マシン再起動時に自動的に起動する様に設定する

Bitbucket Pipelinesでセルフホストランナーを構成する場合、デフォルトではPowershellスクリプトを使い、手動で起動する必要があります。
この場合、何らかの事情でマシンを再起動した際に、マシンに接続してランナープログラムを手動で再起動してやる必要が出てきて面倒です。
GitHub ActionsではWindowsはデフォルトでサービスとして動作しているので簡単に自動化ができるのですが、Bitbucket Pipelinesの場合は自動化するのにひと手間掛かります。
この記事では、備忘録的にBitbucket Pipelinesランナーをマシン再起動時に自動実行する方法について残しておきます。また、構成したランナー上でUnityを動かした際に多少詰まった事があったため、その内容についても触れています。
続きを読むPEG Parserで.srtと.vttのパーサーを書いてみた話

こんにちは、エンジニアの渡辺(@mochi_neko_7)です。
今回は映像の字幕テキストを扱うためのフォーマットである SubRip Subtitle (.srt) と WebVTT (.vtt) のパーサーを PEG (Parsing Expression Grammar) を用いて Rust で実装してみた話を紹介します。
唐突ですが、OpenAI の audio/transcriptions API の response_format の説明に
The format of the transcript output, in one of these options:
json,text,srt,verbose_json, orvtt.
とありますよね。
json, text,verbose_json はすぐに分かりますが、srt と vtt を見たことがなかったので調べてみるとそれぞれ、SubRip Subtitle、WebVTT と呼ばれる映像の字幕テキストのフォーマットと知りました。
crates.io で検索してみるとそれっぽい crate がいくつかあるものの、分かりやすくメジャーに使われているものがなく、自分でパーサーを書く経験をしてみたいことから、自分で crate を書くことにしました。
SubRip Subtitle と WebVTT は別のフォーマットではありますが、WebVTT が SubRip Subtitle の発展として作成されたものらしく構造が似ているため、二つを同時に実装してもそれほど手間は変わりませんでした。
テキストファイルのパーサーを自分で書きたい方、特に PEG Parser の使用例として参考になれば幸いです。
環境
- Rust
v1.75.0 - rust-peg
v0.8.2 - subtp
v0.2.0
また本記事で紹介する実装は下記の Repository もしくは crate で利用可能ですので併せてご覧ください。
https://crates.io/crates/subtpcrates.io
PEG Parserとは
PEG (Parsing Expression Grammar) に関しては下記記事で詳しく解説されています。
Rust 向けには rust-peg (パッケージ名は peg) という crate を利用できます。
マクロベースの API で一見とっつきづらいように見えますが、Result ベースのエラーハンドリングも対応されていて、小さい単位の rule を使いまわせる点がプログラミングっぽいです。
一点、 rule を module を跨いで再利用できないのがちょっと使いづらいくらいでしょうか。
今回はこちらの rust-peg を使用して各フォーマットのパーサーを書いていきます。
SubRip Subtitle (.srt)
SubRip Subtitle の正式な仕様書が見つからなかったのでいくつかのページを参照しつつ、パーサーを定義していきます。
典型的には、次の Subtitle ブロック
1 00:00:01,000 --> 00:00:06,000 Hello, world!
を空行を挟んで複数記述したもの、例えば
1 00:00:00,498 --> 00:00:02,827 - Here's what I love most about food and diet. 2 00:00:02,827 --> 00:00:06,383 We all eat several times a day, and we're totally in charge 3 00:00:06,383 --> 00:00:09,427 of what goes on our plate and what stays off.
といったものが SubRip Subtitle の基本フォーマットです。
上記サンプルは こちら からお借りしました。
ブロックの構造は上から連番の番号、開始と終了のタイムスタンプ、複数行可能な字幕テキスト、なので例えば
pub struct SrtSubtitle { pub sequence: u32, pub start: SrtTimestamp, pub end: SrtTimestamp, pub text: Vec<String>, } pub struct SrtTimestamp { pub hours: u8, pub minutes: u8, pub seconds: u8, pub milliseconds: u16, }
のようにデータ構造を定義できます。(ここでは簡単のために derive とコメントは省略しています。)
肝心のパーサーの定義は、peg::parser! マクロを使って定義をします。
peg::parser! { grammar srt_parser() for str { // rules } }
PEG では要素分解して rule を記述し再利用できますので、まず細かいパーツのパーサーから一つずつ定義していきます。
先頭の連番は1以上の整数ですが、例えば u32 の範囲を想定して下記のように rule を書けます。
rule number() -> u32 = n:$(['0'..='9']+) {? n.parse().or(Err("number in u32")) }
構文としては、rule {rule名} ({引数}) -> {戻り値の型} = {rule定義} { {パース処理} } のような形式で記述をします。
rule 定義の n:$(['0'..='9']+) は、'0'..='9' の文字(つまり数字)が一つ以上のものを変数名 n と定義する、という意味です。
この変数 n をパース処理内で利用することができ、今回は n.parse() で u32 にパースしています。
{? ... } の ? は { ... } 内でエラーを扱いたい場合、つまりパース処理の戻り値を Result にしたい場合に使用します。
パースに失敗する、例えば数字以外や u32 の範囲を超える場合には Err を返します。
同様に二桁、三桁の数字の rule を定義し、その組み合わせのタイムスタンプを定義しましょう。
rule two_number() -> u8 = n:$(['0'..='9']['0'..='9']) {? n.parse().or(Err("two-digit number")) } rule three_number() -> u16 = n:$(['0'..='9']['0'..='9']['0'..='9']) {? n.parse().or(Err("three-digit number")) } rule timestamp() -> SrtTimestamp = hours:two_number() ":" minutes:two_number() ":" seconds:two_number() "," milliseconds:three_number() { SrtTimestamp { hours, minutes, seconds, milliseconds, } }
hours:two_number() のように記述することで自分で定義した rule を利用することができます。
ちなみに SubRip Subtitle のミリ秒の区切り文字が . ではなく , なのはフランス由来のもののようで、WebVTT では . が使用されることに注意します。
次にテキスト部分のパース処理も定義していきますが、その前に空白や改行コードの rule を定義しておくと便利です。
rule whitespace() = [' ' | '\t'] rule newline() = "\r\n" / "\n" / "\r"
SubRip Subtitle の字幕テキストの部分は複数行の記述が可能なので、Vec<String> にパースする rule を定義します。
rule multiline() -> Vec<String> = !(whitespace() / newline()) lines:$(!(whitespace()+ newline()) (!newline() [_])+ newline()) ++ () { lines .iter() .map(|l| l.to_string().trim().to_string()) .collect() }
これまでより少し複雑に見えるかと思いますので分解して説明します。
先頭の !(whitespace() / newline()) は否定先読みで、文字の先頭に空白や改行が入らないよう制御しています。
!(whitespace()+ newline()) も同様に空白のみの行を入れないようにするための制御です。
!newline() [_] が改行を含まない任意の文字なので、(!newline() [_])+ は1文字以上の文字列に相当します。
すると (!newline() [_])+ newline() は何かしらの文字と改行のパターン、つまり文字が書かれている行に相当します。
x ++ y という構文は x を y を区切りとして1つ以上繰り返すパターンなので、((!newline() [_])+ newline()) ++ () は文字の書かれている行を一行以上含む、という rule になります。
これに余計な空白を無視して Vec<String> にしているのがイテレータの処理部分です。
最後にこれらの組み合わせとして、Subtitle のブロックとその繰り返しのパーサーを定義します。
rule separator() = !(newline() newline()) (whitespace() / newline())+ rule subtitle() -> SrtSubtitle = sequence:number() separator() start:timestamp() separator()* "-->" separator()* end:timestamp() separator() text:multiline() { SrtSubtitle { sequence, start, end, text } } rule srt() -> SubRip = (whitespace() / newline())* subtitles:subtitle() ** (newline()+) (whitespace() / newline())* { SubRip { subtitles, } }
Subtitle の各要素の区切りは空白でも改行でもよく、かつ余計な空白も許容するよう separator の rule を定義しています。
SubRip 全体のパーサーは SrtSubtitle の配列ですが、前後やブロック間の余計な空白や改行を許容するよう柔軟性を持たせています。
ブロックそれぞれも改行ではなくスペースだけで区切るケースや、--> の両端にスペースを入れない場合もあるらしいので、可能な限り柔軟性を持たせておきます。
最終的なコードは下記をご覧ください。
データ構造:
パーサー:
WebVTT (.vtt)
WebVTT は SubRip Subtitle をベースにしつつも、Sequence Number の自由度が高かったり、NOTE でコメントを記述できたり、表示方法に関する設定ができたりと細かい使い勝手を考慮して作られているようです。
その分 SubRip Subtitle と比較すると仕様は複雑ですが、幸いなことに丁寧な仕様書が公開されているのでこれに従って実装すれば困りません。
オプションで許容されるパターンが多かったり、設定系の種類もオプションも多いので物量が多いですが、基本は SupRip Subtitle の時と同じ要領です。
全て解説すると長くなってしまうのでここでは割愛しますが、気になる方は下記のコードをご覧ください。
データ構造:
パーサー:
サンプル
実際に OpenAI の audio/transcriptions API の response_format に srt と vtt を指定した場合の結果のサンプルと、そのパース結果に対応するデータを紹介します。
データ構造にはオプションの要素が多いので、適宜 Default trait を利用すると綺麗に書けます。
解析する音源はたまたま手元にあった Style-Bert-VITS-2 の合成音声を利用しました。
SubRip Subtitle
1 00:00:00,000 --> 00:00:07,000 ずんだもん、ずんこに何度かずんだもちを食べさせられてきたけど、これって実はとも食いじゃーう
<->
use subtp::srt::{SubRip, SrtSubtitle, SrtTimestamp} let subrip = SubRip { subtitles: vec![ SrtSubtitle { sequence: 1, start: SrtTimestamp { seconds: 0, ..Default::default() }, end: SrtTimestamp { seconds: 7, ..Default::default() }, text: vec!["ずんだもん、ずんこに何度かずんだもちを食べさせられてきたけど、これって実はとも食いじゃーう".to_string()], ..Default::default() }, ], };
WebVTT
WEBVTT 00:00:00.000 --> 00:00:07.000 ずんだもん、ずんこに何度かずんだもちを食べさせられてきたけど、これって実はとも食いじゃーう
<->
use subtp::vtt::{WebVtt, VttCue, VttTimings, VttTimestamp} let webvtt = WebVtt { blocks: vec![ VttCue { timings: VttTimings { start: VttTimestamp { seconds: 0, ..Default::default() }, end: VttTimestamp { seconds: 7, ..Default::default() }, }, payload: vec!["ずんだもん、ずんこに何度かずんだもちを食べさせられてきたけど、これって実はとも食いじゃーう".to_string()], ..Default::default() } .into(), ], ..Default::default() };
おわりに
SubRip Subtitle や WebVTT はこれまで触ったことのないファイルフォーマットでしたが、これらを通して PEG Parser の使い方を理解することができました。
PEG は直感的でない挙動もするという話も聞きますが、テストコードを書きながらデバッグしていけば PEG の仕様の理解も深まっていくと思います。
自分でテキストのパーサーを書いてみたい方に参考になれば幸いです。
Rust/Actix-webでToDoアプリのAPIを実装してみる
はじめに
こんにちは、エンジニアのクロ(@kro96_xr)です。
前回の執筆でRustのWebフレームワークについて調査してみました。
今回の記事では、その中からActix-webとORMツールのDieselを使用して、シンプルなToDoアプリのバックエンドAPIを開発してみました。
前回の記事はこちら。
環境構築
環境
今回使用したバージョンは以下になります。
- cargo 1.76.0
- rustc 1.76.0
- actix-web 4.5.1
- diesel 1.4.8
- dieselは2.1系が最新ですがバージョンを上げたら動かなかったため一旦古いバージョンのままです。
- dotenv 0.15
- dotenvは2020年のリリースで止まっておりunmaintained状態なので注意が必要かもしれません。
- postgres 16.2
dotenvについて詳しくはこちら
プロジェクトのセットアップ
まず、新規でRustプロジェクトを作成します。
cargo new todo_api --bin cd todo_api
次に'Catgo.toml'ファイルに依存関係を追加します。
[dependencies]
actix-web = "4"
actix-rt = "2"
tokio = { version = "1", features = ["full"] }
diesel = { version = "1.4", features = ["postgres", "r2d2", "chrono", "table"] }
dotenv = "0.15"
serde = { version = "1.0", features = ["derive"] }
log = "0.4.14"
次にプロジェクトのルートに'docker-compose.yml'ファイルを作成して、アプリケーションサービスとPostgreSQLのサービスを定義します。
postgresの環境変数は適宜直してください。
今回は開発用ということでsrcをvolumeとすることで開発中のソースコードの変更がコンテナに即時反映されるようにしています。
version: '3' services: todo_api: build: ./todo_api volumes: - ./todo_api/src:/usr/src/todo_api/src - ./todo_api/Cargo.toml:/usr/src/todo_api/Cargo.toml - ./todo_api/Cargo.lock:/usr/src/todo_api/Cargo.lock ports: - "8000:8000" depends_on: - db environment: - DATABASE_URL=postgres://user:password@db/todo_db db: image: postgres:latest environment: POSTGRES_USER: user POSTGRES_PASSWORD: password POSTGRES_DB: todo_db ports: - "5432:5432" volumes: - ./db_data:/var/lib/postgresql/data volumes: db_data:
Dockerfileは以下の通りです。今回は開発用ということで
FROM rust:latest
WORKDIR /usr/src/todo_api
COPY Cargo.toml Cargo.lock ./
# ビルドのキャッシュレイヤーを作成するためにダミーのソースファイルを作成
RUN mkdir src && \
echo "fn main() {println!(\"if you see this, the build broke\")}" > src/main.rs
# 依存関係だけを先にビルド
RUN cargo build --release
# 実際のソースコードをコピー
COPY . .
# 再度ビルドを実行し、変更を反映
RUN touch src/main.rs && \
cargo build --release
# コンテナ起動時にアプリケーションを実行
CMD ["cargo", "run", "--release"]
Dieselのセットアップ
docker-composeを使ってデータベースサービスを立ち上げます。
docker-compose up -d db
次にDiesel CLIを使用してデータベースのセットアップとマイグレーションを行います。
echo DATABASE_URL=postgres://user:password@localhost:5432/todo_db > .env diesel setup diesel migration generate create_todos
'up.sql'と'down.sql'を編集してテーブルを作成します。 今回はシンプルにタイトルと完了フラグだけにします。
up.sql
CREATE TABLE todos ( id SERIAL PRIMARY KEY, title VARCHAR NOT NULL, completed BOOLEAN NOT NULL DEFAULT FALSE, created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP );
down.sql
DROP TABLE todos;
マイグレーションを実行します。
diesel migration run
API実装
次に、実際にactix-webを使用してエンドポイントを実装していきます。
DBコネクションの実装
まず、DBコネクション周りの実装を行います。 今回はr2d2クレートを使ってコネクションプールを実装します。
db.rsを作成し以下のように実装します。
後ほどmain.rsからestablish_connection_pool関数を呼び出し、コネクションプールを作成します。
use diesel::prelude::*; use diesel::r2d2::{self, ConnectionManager}; pub type DbPool = r2d2::Pool<ConnectionManager<PgConnection>>; pub fn establish_connection_pool(database_url: &str) -> DbPool { let manager = ConnectionManager::<PgConnection>::new(database_url); r2d2::Pool::builder() .build(manager) .expect("Failed to create pool.") }
メイン関数の実装
main.rsを実装します。
環境変数からデータベースURLを読み込み、establish_connection_pool関数を呼んでコネクションプールを作成。
作成したコネクションプールをapp_data関数に渡してアプリケーションのルートデータとして登録します。
#[actix_web::main] async fn main() -> std::io::Result<()> { let database_url = env::var("DATABASE_URL").expect("DATABASE_URL must be set"); let pool = db::establish_connection_pool(&database_url); // 略 }
ルーティングを設定し、APIエンドポイントとして公開しておきます。 ハンドラーはとりあえずダミーで実装しておきます。全体は以下。
#[macro_use] extern crate diesel; use std::env; use actix_web::{web, App, HttpServer, Responder, HttpResponse}; async fn get_todo_handler() -> impl Responder { HttpResponse::Ok().body("Get todo") } async fn create_todo_handler() -> impl Responder { HttpResponse::Ok().body("Create todo") } async fn update_todo_handler() -> impl Responder { HttpResponse::Ok().body("Update todo") } async fn delete_todo_handler() -> impl Responder { HttpResponse::Ok().body("Delete todo") } #[actix_web::main] async fn main() -> std::io::Result<()> { dotenv().ok(); let database_url = env::var("DATABASE_URL").expect("DATABASE_URL must be set"); let pool = db::establish_connection_pool(&database_url); HttpServer::new(move || { App::new() .app_data(web::Data::new(pool.clone())) .route("/todos", web::get().to(get_todo_handler)) .route("/todos", web::post().to(create_todo_handler)) .route("/todos/{id}", web::put().to(update_todo)) .route("/todos/{id}", web::delete().to(delete_todo)) }) .bind("0.0.0.0:8000")? .run() .await }
モデルとスキーマの定義
models.rsにデータモデルを定義します。Todo構造体はデータベースのレコードを表しています。
NewTodoとUpdateTodoの違いはOptionになっているかどうかです。
use serde::{Deserialize, Serialize}; use crate::schema::todos; #[derive(Debug, Serialize, Deserialize, Queryable)] pub struct Todo { pub id: i32, pub title: String, pub completed: bool, pub created_at: chrono::NaiveDateTime, pub updated_at: chrono::NaiveDateTime, } #[derive(Insertable, Deserialize)] #[table_name="todos"] pub struct NewTodo { pub title: String, pub completed: bool, } #[derive(Deserialize, Serialize, AsChangeset)] #[table_name = "todos"] pub struct UpdateTodo { pub title: Option<String>, pub completed: Option<bool>, }
schema.rsにはDieselによって自動生成されるテーブルのスキーマが含まれます。
このスキーマを使用してDieselのクエリビルダからデータベース操作が可能になります。
// @generated automatically by Diesel CLI. diesel::table! { todos (id) { id -> Int4, title -> Varchar, completed -> Bool, created_at -> Timestamp, updated_at -> Timestamp, } }
CRUD操作の実装
todo.rsにToDoテーブルに関連したデータベース操作を行う関数を実装します。
use chrono::Utc; use crate::models::{Todo, NewTodo, UpdateTodo}; use crate::schema::todos::dsl::*; use diesel::prelude::*; use actix_web::{web, error, Error}; use crate::db::DbPool; pub async fn get_todos(pool: web::Data<DbPool>) -> Result<Vec<Todo>, Error> { let conn = pool.get().map_err(|_| error::ErrorInternalServerError("Failed to get db connection from pool"))?; web::block(move || todos.load::<Todo>(&conn)) .await .map_err(|_| error::ErrorInternalServerError("Error loading todos")) .and_then(|res| res.map_err(|_| error::ErrorInternalServerError("Error loading todos"))) } pub async fn create_todo( pool: web::Data<DbPool>, new_todo: web::Json<NewTodo>, ) -> Result<Todo, Error> { let conn = pool.get().map_err(|_| error::ErrorInternalServerError("Failed to get db connection from pool"))?; web::block(move || diesel::insert_into(todos) .values(&*new_todo) .get_result::<Todo>(&conn) ) .await .map_err(|_| error::ErrorInternalServerError("Error creating todo")) .and_then(|res| res.map_err(|_| error::ErrorInternalServerError("Error loading todos"))) } pub async fn update_todo( pool: web::Data<DbPool>, todo_id: web::Path<i32>, update_todo: web::Json<UpdateTodo>, ) -> Result<Todo, Error> { let conn = pool.get().map_err(|_| error::ErrorInternalServerError("Failed to get db connection from pool"))?; web::block(move || diesel::update(todos.find(*todo_id)) .set(( update_todo.into_inner(), updated_at.eq(Utc::now().naive_utc()), // `updated_at`を現在のタイムスタンプに設定 )) .get_result::<Todo>(&conn) ) .await .map_err(|_| error::ErrorInternalServerError("Error update todo")) .and_then(|res| res.map_err(|_| error::ErrorInternalServerError("Error loading todos"))) } pub async fn delete_todo( pool: web::Data<DbPool>, todo_id: web::Path<i32>, ) -> Result<Todo, Error> { let conn = pool.get().map_err(|_| error::ErrorInternalServerError("Failed to get db connection from pool"))?; web::block(move || diesel::delete(todos.find(*todo_id)) .get_result::<Todo>(&conn) ) .await .map_err(|_| error::ErrorInternalServerError("Error update todo")) .and_then(|res| res.map_err(|_| error::ErrorInternalServerError("Error loading todos"))) }
ハンドラの更新
main.rsを修正し、各CRUD操作に対応するハンドラ関数を実装します。 これらのハンドラ関数がエンドポイントが呼び出された時に実行されます。
async fn get_todo_handler(pool: web::Data<DbPool>) -> impl Responder { match todo::get_todos(pool).await { Ok(todos) => HttpResponse::Ok().json(todos), Err(_) => HttpResponse::InternalServerError().finish(), } } async fn create_todo_handler(pool: web::Data<DbPool>, new_todo: web::Json<models::NewTodo>) -> impl Responder { match todo::create_todo(pool, new_todo).await { Ok(todo) => HttpResponse::Ok().json(todo), Err(_) => HttpResponse::InternalServerError().finish(), } } async fn update_todo_handler(pool: web::Data<DbPool>, todo_id: web::Path<i32> ,update_todo: web::Json<models::UpdateTodo>) -> impl Responder { match todo::update_todo(pool, todo_id, update_todo).await { Ok(todo) => HttpResponse::Ok().json(todo), Err(_) => HttpResponse::InternalServerError().finish(), } } async fn delete_todo_handler(pool: web::Data<DbPool>, todo_id: web::Path<i32> ) -> impl Responder { match todo::delete_todo(pool, todo_id).await { Ok(todo) => HttpResponse::Ok().json(todo), Err(_) => HttpResponse::InternalServerError().finish(), } }
以上、実装完了です。
実装内容は以下のリポジトリにまとめてあります。
GitHub - krocks96/rust-backend-playground
おわりに
ブログ執筆や実装に割ける時間が少なくChatGPTに相談しつつ実装したのですが、その影響で一部クレートのバージョンが一部低い部分がありました。
特にDieselのメジャーバージョンが1から2になっており、詳細を調べて反映させたかったのですがその辺りは次回としたいと思います。